PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
구운밤이다
2021. 3. 28. 11:31
728x90
반응형
Abstract
포인트 클라우드는 중요한 기하학적 데이터 구조 유형입니다. 불규칙한 형식으로 인해 대부분의 연구자들은 이러한 데이터를 일반 3D voxel 그리드 또는 이미지 모음으로 변환합니다. 그러나 이로 인해 데이터가 불필요하게 방대해지고 문제가 발생합니다. 이 논문에서 우리는 입력 포인트의 순열 불변성을 잘 존중하는 포인트 클라우드를 직접 소비하는 새로운 유형의 신경망을 설계합니다. PointNet이라는 이름의 우리 네트워크는 객체 분류, 부분 분할에서 장면 의미 분석에 이르기까지 다양한 애플리케이션을위한 통합 아키텍처를 제공합니다. 간단하지만 PointNet은 매우 효율적이고 효과적입니다. 경험적으로, 그것은 동등한 수준의 강력한 성능을 보여줍니다. 이론적으로 우리는 네트워크가 학습 한 내용과 입력 섭동 및 손상과 관련하여 네트워크가 강력한 이유를 이해하기위한 분석을 제공합니다.
Intro
기존의 Convolutional Architecture들은 weight sharing과 kernel 최적화등의 이유로 2D 이미지 혹은 3D Voxel 형태의 regular한 데이터를 입력으로 사용했었습니다. 3D Point Cloud는 irregular한 데이터 특성 때문에 2D 이미지 혹은 3D Voxel 형태로 변환해서 사용하였고 이는 불필요하게 커다란 형태로 표현되거나 정보의 손실이 발생했습니다.
이러한 문제점들을 해결하기 위해 저자들은 3D Point Cloud를 변환하지 않고 directly하게 입력으로 사용하는 신경망 모델PointNet을 제안합니다. key contribution은 다음과 같습니다.
정렬되지 않은(unordered) 3D Point Cloud 데이터를 위한 Deep Net Architecture 제안
제안한 Architecture를 이용한 3D Shape Classification, Shape part segmentation, Scene Semantic Parsing의 성능
stability와 efficiency 측면에서 실험적 그리고 이론적인 분석
3D feature을 시각화하고 Architecture의 성능을 직관적으로 설명
Problem Statement
Point Cloud는 3D point들로 표현됩니다. Pi는 각각 (x,y,z) 좌표 정보를 가지고 있습니다. Object Classification에서는 Point Cloud를 입력으로 k개의 class에 대해 k개의 점수를 출력합니다. Sementic Segmentation에서는 한개의 Object 혹은 3D Scene의 일정 부분이 입력으로 사용되고 n개의 point들에 각각 m개의 semantic subcatergories 점수를 출력합니다.
그림 1. PointNet의 애플리케이션. 복셀화 또는 렌더링없이 raw 포인트 클라우드 (포인트 세트)를 소비하는 새로운 딥넷 아키텍처를 제안합니다. 글로벌 및 로컬 포인트 기능을 모두 학습하는 통합 아키텍처로 여러 3D 인식 작업에 대해 간단하고 효율적이며 효과적인 접근 방식을 제공합니다.
unordered, unstructured data인 point data를 위와 같이 rendering하지 않고 직접 다루기 위해서 다음 두 가지 성질을 만족시켜야 한다고 말한다.
Permutation invariantpoint 들이 unordered 상태로 주어지기 때문에 네트워크는 어떠한 순서로 오더라도 output이 달라지지 않도록 해야한다.
즉, n개의 point가 있을때 이들이 얻어지는 순서의 경우의 수는 n!개 만큼 존재한다. 따라서 n! 경우의 수 모두에 대해서 output 결과는 동일하도록 network는 동작해야 한다. 이를 permutation invariant라고 한다.
Rigid motion invariantRigid motion은 transformation을 해도 point들 간의 distance와 방향은 그대로 유지되는 transformation을 말한다.
여기에는 다음 네 종류의 transformation이 포함된다.
(1) Translation : 도형의 모든 점이 동일한 방향으로 동일한 거리만큼 이동된다.
(2) Rotation : 특정 점을 기준으로 도형이 회전된다.
(3) Reflection : 특정 직선을 기준으로 도형이 대칭이동된다.
(4) Glide reflection : reflection과 translation을 통해 도형이 이동된다.
Deep Learning on Point Sets
입력 데이터의 문제점
Unordered.첫번째로 Point들은 정렬되어있지 않습니다. 이미지의 픽셀 배열이나 Volumetric grid의 Voxel 배열과 다르게 Point Cloud는 Point들의 집합으로 이루어져 있어 명확한 정렬이 없습니다. 다시말해 Point Cloud를 입력으로하는 Network는 N개의 Point들을 입력으로 사용할때 N!개의 순열(permutation)이 생기고 연산의 결과가 입력 순서에 불변해야 합니다.Point Cloud를 구성하는 Point에는 순서가 없기 때문에 그림의 왼쪽 데이터와 오른쪽 데이터는 같다는 뜻입니다.
Interaction among points두번째로 Point들은 distance metric 공간에 있습니다. 이것은 Point들이 독립적으로 의미를 갖는것이 아니라 근접한 Point들과 Subset으로 구성됨에 따라 의미를 갖는다는 것을 뜻합니다. 이를 local feature라고 합니다. 따라서 모델은 인접한 Point들의 local structure를 학습해야하고 또한 local structure들 사이의 결합도 학습해야 합니다.
3. Invariance under transformations.
마지막으로 기하학적인 Object로써 Point set의 학습된 표현(learned representation)은 특정한 변환에 대해 불변해야합니다. 예를 들어서 Point 전체에 대한 회전 변환이나 이동 변환은 global Point Cloud의 category나 Point들의 segmentation을 변화시키지 않습니다.
입력 데이터가 갖는 3가지 문제를 해결할수 있는 모델을 그림과 같이 제안하였고 모델을 구성한 이유를 이론적인 근거를 통해 설명합니다.
Symmetry Function for Unordered Input
Permutation invariant ⇒ 전략은 3가지가 있습니다.
입력 데이터를 canonical order로 정렬하는 법. canonical order는 정규 형식 또는 표준 형식을 따르는 정렬방법을 의미하고 어떠한 특정한 정렬 알고리즘을 뜻하지는 않습니다.
입력 데이터를 RNN을 통해 sequence하게 학습하고 이때 입력 데이터가 가질수 있는 모든 permutation에 대해서 같은 결과가 나오도록 학습하는 법
각각의 Point의 정보를 통합하는 symmetric function을 사용하는 법. symmetric function의 예로는 입력의 순서에 상관없이 일정한 결과를 출력하는 더하기(+) 연산과 곱하기 연산(x)이 있습니다.
1번 실험 결과 - 입력 데이터를 canonical order로 정렬하는 법이 쉬운 해결책으로 보이지만 높은 차원의 경우 stable한 정렬방법이 존재하지 않습니다. 예를 들어 (x,y,z) 3차원으로 이루어진 Point 데이터를 일정한 기준으로 정렬한다는 것은 3차원 데이터를 1차원으로 mapping 하는 방법이 존재한다는 뜻이고 차원의 감소에 의해 일반적으로는 이루어질수 없는 방법입니다. 저자들은 정렬된 Point set을 통해 실험했을때 정렬되지 않은 Point set과 비교하여 아주 약간의 성능 향상이 이루어졌다고 나타냅니다.
2번 실험 결과 - RNN을 이용해 학습하는 경우를 생각해 보겠습니다. Point set의 permutation에 따라 다양한 sequence를 학습하게 되면 RNN이 입력 순서에 불변성을 갖을수 있을것으로 예상할수 있습니다. 하지만 RNN은 sequence가 Point Cloud에 비해 상대적으로 작은 수십개 정도일때 강력한 성능을 발휘하지만 평균적으로 수천개 혹은 수만개로 이루어진 Point Cloud의 경우 학습하기 매우 어렵습니다. 이또한 RNN을 기반으로한 모델을 실험하였고 논문에서 제안한 PointNet에 비해 떨어지는 성능을 보입니다.
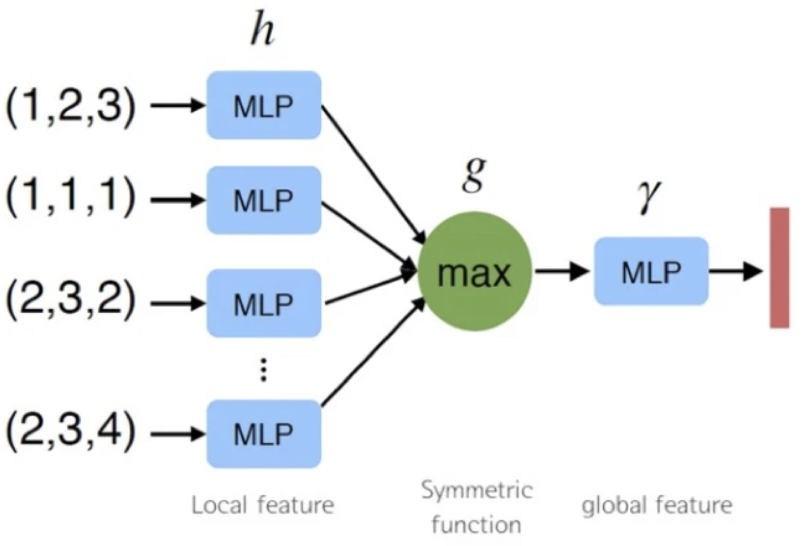
그림 5. 순서 불변성을 달성하기위한 세 가지 접근 방식. 포인트에 적용된 다중 레이어 퍼셉트론 (MLP)은 뉴런 크기가 64,64,64,128,1024 인 5 개의 은닉 레이어로 구성되며 모든 포인트는 단일 MLP 사본을 공유합니다. 출력에 가까운 MLP는 크기가 512,256 인 두 개의 레이어로 구성됩니다.
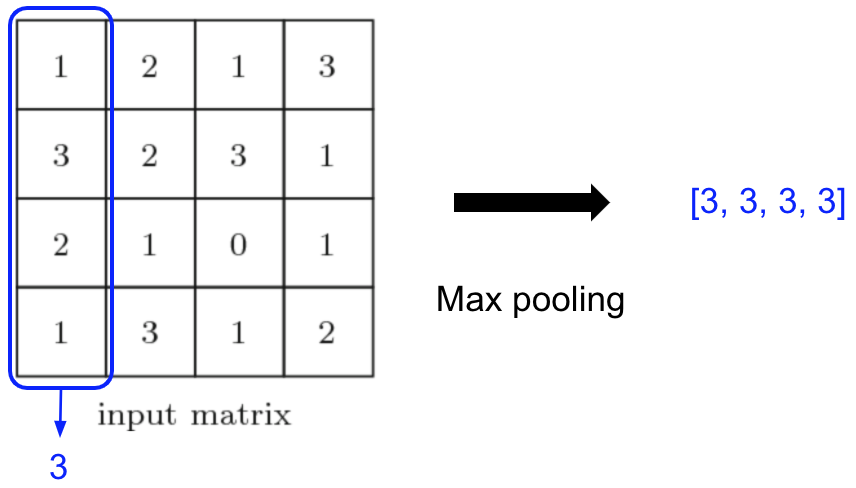
3번 실험 결과 - 논문은 마지막 전략 symmetric function을 통해 문제를 해결합니다. 메인 아이디어는 다음의 수식과 같이 symmetric function을 적용하여 일반 함수를 근사하는 방식을 사용하는 것입니다. (Max pooling은 f(x, y, z) = max(x, y, z) = max(y, x, z)이므로 당연히 Permutation invariant)추가적으로 feature extraction을 위한 network 역시 존재하는데 이는 아래와 같이 각 point마다 mlp를 통해 feature를 생성한다.위 Symmetric function architecture 에서처럼 각 point마다 mlp를 통해 feature를 생성하고 생성된 feature를 column-wise 형식으로 max pooling을 거친다. 논문에서는 각 point마다 mlp를 통해 1024개의 feature를 생성하는데 이때 사용되는 mlp의 weight는 모든 점마다 동일하게 사용된다(= weight sharing). 이렇게 각 점마다 1024개의 feature를 만드는 과정은 input data의 perturbation(작은 변화)에 대해서 robust하도록 만든다.
Column-wise max pooling이 뜻하는 바는 n개 점에서 각 점마다 1024개의 feature를 뽑아내고 모든 점에대해 i번째 feature를 기준으로 max값을 뽑는 task이므로 global feature를 1024개 뽑는다고 할 수 있다.
$$1)\ f(\{x_1,...,x_n\})≈g(h(x_1),...,h(x_n))$$
$$2)\ f:2^{R^N}→R,h:R^N→R^K and\ g:R^k×⋯×R^K→R$$
그림 2
PointNet 아키텍처. 분류 네트워크는 n 개의 포인트를 입력으로 사용하고 입력 및 특성 변환을 적용한 다음 최대 풀링으로 포인트 특성을 집계합니다. 출력은 k 클래스에 대한 분류 점수입니다. 분할(Segmentation) 네트워크는 분류 네트워크의 확장입니다. 글로벌 및 로컬 기능을 연결하고 점수 당 출력을 표시합니다. “mlp”는 다층 퍼셉트론을 나타내며 괄호 안의 숫자는 레이어 크기입니다. Batchnorm은 ReLU를 사용하는 모든 계층에 사용됩니다. 드롭 아웃 레이어는 분류 망의 마지막 mlp에 사용됩니다.
1번 식 그대로 네트워크 구성. 복수 개의 mlp(식1- h)를 통해 각각 n개의 점에서 1024개의 feature를 만들고 max pooling(식1 - g)을 통해 global feature 생성 ⇒ 다시 mlp(식1-r)를 거쳐 k개 클래스에 대한 점수가 나온다.모델의 구조도에서 Input Points (n×3)는 (x,y,z)로 이루어진 3차원 Point가 n개라는 의미입니다. 그리고 이 Point들이 Input Transform과 MLP 그리고 Feature Transform을 거쳐 (n×1024)의 Feature로 바뀌게 됩니다. 결국 각각의 Point에 대해서 3차원의 정보를 1024차원의 정보로 확장했다는 의미로 해석할수 있습니다. 이 부분이 수식에서 N차원의 벡터를 K차원의 벡터로 Mapping하는 함수 h 라고 볼수 있겠습니다. Symmetric 함수 g는 (n×1024)를 입력으로 하는 Max Pooling에 해당합니다. ⇒ "Symmetric function으로 max pooling 함수를 제시한다"
Segmentation Task
설명 1 - classification은 input전체에 대해서 하나의 output(어떤 class인지) 만을 계산하는 task이지만 segmentation은 각 pixel별로 output(pixel/point별로 어떤 class에 속하는지) 를 계산해야 하므로 local & global 정보가 모두 필요하다. 이 논문에서 선택한 방법은 64개의 feature가 생성된 intermediate layer에 max pooling을 거쳐 생성된 1024개의 feauture를 concatenate 시키는 것이다. 즉, 각 point마다 생성된 개개인의 local feature 64개 뒤에 global feature 1024개도 뒤에 붙여줌으로써 local & global 정보를 결합한다. 이후에는 다시 mlp를 통해서 point별로 class들에 대한 score m개가 나와 nxm의 shape이 output으로 나온다.
설명 2 - Local and Global Information Aggregation 수식 f()≈g(h(x1),...,h(xn))의 입력이 Subset이기 때문에 집합 으로 만들수 있는 Subset중 K개를 입력으로 사용할 경우 출력은 f1,...,fK로 총 K개의 실수가 됩니다. 이를 벡터 형태 [f1,...,fK]로 구성하고 n개의 Point에 대한 global feature라고 합니다. 모든 Point에 대한 global feature를 벡터 형태로 나타낼 수 있으므로 이를 이용해서 SVM이나 MLP를 통해서 간단히 Classification을 수행할 수 있습니다. 하지만 Segmentation은 local feature와 global feature를 모두 필요로 하기 때문에 그림에서 볼수있듯이 Classification Network의 local feature와 global feature를 병합하여 Segmentation Network의 입력으로 사용합니다. ⇒ 이를 통해 Point의 지역적인 정보를 학습
h는 N차원 벡터를 K차원의 벡터로 Mapping하는 함수입니다. 현재 다루고 있는 데이터에서는 3차원의 Point를 K차원의 벡터로 mapping하는 함수라고 할 수 있고 h에 의해 출력되는 RK를 Point 한개에 대한 local feature라고 볼수있습니다. g는 symmetric function입니다. g의 입력으로 사용되는 h(x1)h(x1), h(x3)h(x3), h(xn)h(xn)들의 순서가 바뀌어도 출력이 일정합니다. 즉 n개의 Point들로 이루어진 데이터의 Subset을 입력으로 사용하는 일반함수 f를 함수 h와 g를 사용하여 근사합니다. h는 multi-layer perceptron network(MLP)를 사용하여 근사할수 있고 g는 max pooling을 사용하여 근사합니다.
최종적으로 point마다 feature를 만드는 mlp와 symmetric function의 역할을 하면서 global feature를 뽑는 max pooling 함수를 통해서 아래와 같은 symmetric function을 구성하게 된다.
n개의 점이 mlp를 통해 nx1024의 shape이 되면 column-wise로 max pooling을 하여 1024개의 output 값이 나오게 된다.
Rigid motion invariant
설명 1 - Introduction에서 설명했듯이 CNN과 같이 동작하기 위해 input에 어떤 transformation이 가해져도 output 결과에는 영향을 끼쳐서는 안된다. point cloud에서는 이를 위해 spatial transformer network(STN)를 이용한다.
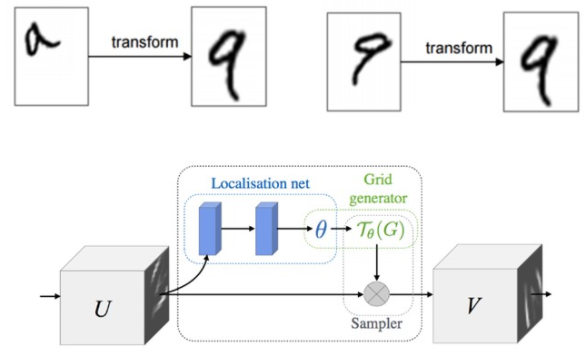
Figure 7. Spatial Transformer Network
STN에서는 image에 대해 rigid motion invariant를 만족시키기 위해 image를 orthogonal하게 만든다.
Figure 7의 기울어진 숫자 9 이미지를 orthogonal하게 만들기 위해 transform을 적용하여 canonoical space로 보낸다.
이 과정을 수행하기 위해 STN에서는 아래와 같이 동작한다.
(1) input image를 canonical space로 보내기 위해 (orthogonal하게 만들기 위해) 어떠한 transformation이 적용돼야 하는지 계산한다.
(2) 계산된 transformation을 기존 input image에 곱하여 변형이 일어나지 않은 모습의 output image를 만든다.
이미지에서 적용되는 위 STN 아이디어를 가져와서 point cloud에서는 T-net을 소개한다.
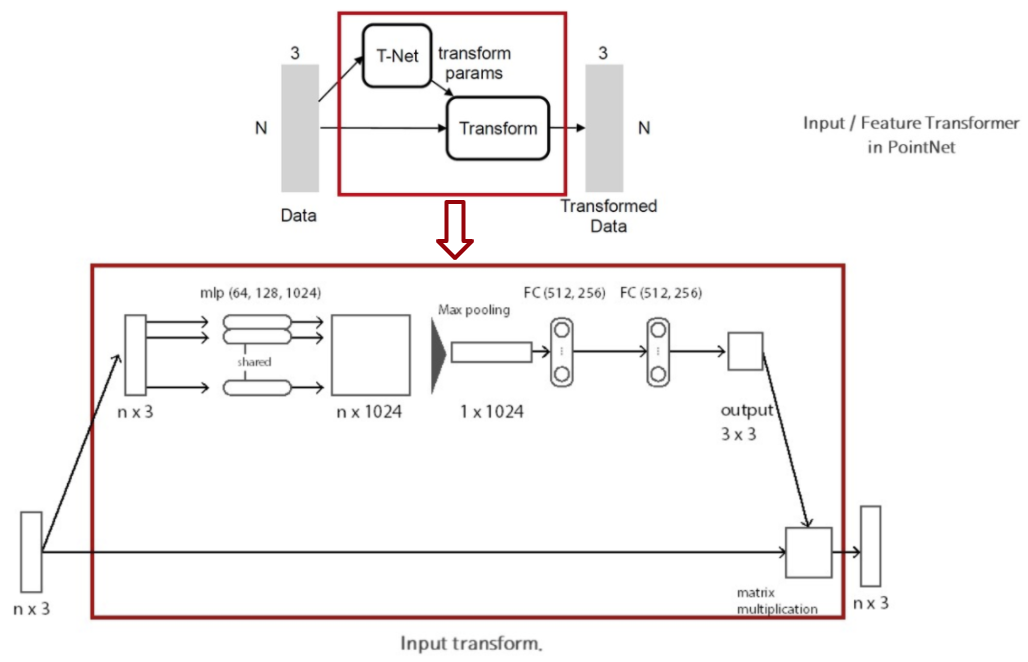
Figure 8. mini pointNet
Figure 7의 STN과 동일한 형태로 mini pointNet은 구성되어 있다. 먼저 T-net에서 point data들을 canonical space로 보내기 위해 적용되어야 하는 transformation matrix를 계산한다. 그리고 input data에 transformation matrix를 곱한다.
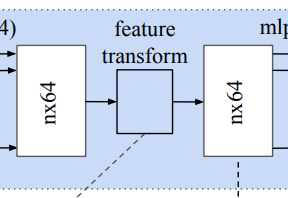
전체 pointNet architecture를 보면 input transform뿐만 아니라 중간에 feature transform도 존재한다.
이때 feature transform에서는 64x64의 transfomation matrix를 predict해야하므로 차원이 커서 optimize시키기 어렵다. 따라서 여기에 정규화 식을 추가하는데 이는 아래와 같다.
$$L_{reg}=∥I−AA^T∥^2_F$$
위 식은 trasformation matrix인 A가 orthogonal matrix가 되도록 하기위한 식이다. (orthogonal matrix x는 xx^T가 I이다. ⇒ 즉 loss func) transformation matrix가 orthogonal matrix가 되면 input matrix(=input 도형)에 곱해도 도형의 원래 고유모양이 바뀌지 않는, rigid motion이 되기 때문이다. 즉, rigid motion에 대응되는 transformation matrix가 되도록 하기 위해 위 정규화 식을 추가하였다.
설명 2 - Joint alignment Network 앞서 언급했던 3가지의 문제중 1. Unordered와 2. Interaction among points는 함수 h와 g를 이용해 함수 f를 근사하는 방법으로 해결했습니다. 3. Invariance under transformation 문제는 Affine Transformation을 추정하는것으로 해결합니다. Affine Transformation은 벡터 공간에서 직선과 평행을 보존하는 변환을 뜻합니다.
모델의 구조도에서 Input Transform과 Feature Transform에 해당하는 Mini-Network 부분입니다. 모델이 추정하는 Affine Transformation은 입력 Point를 Canonical Space의 한 Point로 변환하는 역할을 합니다. Canonical Space란 표준 공간으로 Affine Transformation을 통해 Point를 Canonical Space의 Point로 변환한다는 것은 Point들 간의 직선성과 평행성을 보존하면서 정규화된 공간으로 옮긴다는 것으로 이해했습니다. 다시말해 Point가 위치하는 공간에 대한 정보는 Transformation에 의해 변화할수 있는것이지만 Point들간의 관계에 대한 정보는 Transformation에 의해 변화하지 않기 때문에 Classification이나 Segmentation을 수행할때 Transformation에 의해 변화하지 않는 정보를 활용하기 위함으로 보입니다.
논문에서는 이러한 Affine Transformation matrix를 추정하는 Network를 T-Net이라고 부르며 T-Net 또한 전체 Network와 유사하게 MLP와 Max Pooling으로만 구성되어 있습니다. 이러한 과정을 Point를 Alignment하는 Transform이라고 표현합니다. 유사한 방식으로 Local Feature에도 Alignment를 적용합니다.
Feature의 크기에 따라 Input Transform의 경우 3 x3 Matrix를 근사하였고 Feature Transform은 64 x 64 크기의 Matrix를 근사합니다. 하지만 Feature Transform에서 근사하는 Matrix의 경우 크기가 64 x 64로 Input Transform의 Matrix에 비해 차원이 엄청나게 높기 때문에 Optimization하기에 어렵습니다. 따라서 Feature Transform의 Matrix를 A라고 하고 다음과 같은 수식으로 Loss Function을 설정하여 제약을 둡니다.
$$L_{reg}=∥I−AA^T∥^2_F$$
Matrix A가 직교행렬이 되도록하는 Loss Function입니다. 직교행렬의 정의에 의해 각 행벡터와 열벡터의 크기가 1이 되므로 Matrix를 구성하는 원소들의 범위가 제한적입니다. Input에 대한 Alignment, Feature에 대한 Alignment 총 두번의 Alignment를 거치므로 Transformation에 더욱 Invariant(변화가 없는)한 모델을 학습합니다.
그림들
그림 3. 부품 분할에 대한 정성적(Qualitative) 결과. 16 개 개체 범주 모두에서 CAD 부품 분할 결과를 시각화합니다. 부분 시뮬레이션 된 Kinect 스캔 (왼쪽 블록)과 전체 ShapeNet CAD 모델 (오른쪽 블록)에 대한 결과를 모두 표시합니다.
표 1. ModelNet40의 분류 결과. 우리의 그물은 3D 입력의 deep net 중에서 최첨단을 달성합니다.
표 2. ShapeNet 부품 데이터 세트의 세분화 결과. 메트릭은 포인트에 대한 mIoU (%)입니다. 두 가지 전통적인 방법 [24]과 [26]과 우리가 제안한 3D 완전 컨볼 루션 네트워크 기준과 비교합니다. 우리의 PointNet 방법은 mIoU에서 최첨단을 달성했습니다.
표 3. 장면에서 의미 론적 분할에 대한 결과. 측정 항목은 13 개 클래스 (구조 및 가구 요소와 어수선 함)에 대한 평균 IoU이며 포인트에 대해 계산 된 분류 정확도입니다.
표 4. 장면에서 3D 물체 감지 결과. 메트릭은 3D 볼륨에서 계산 된 임계 값 IoU 0.5의 평균 정밀도입니다.
그림 4. 시맨틱 분할에 대한 정성적 결과. 맨 위 행은 색상이있는 입력 포인트 클라우드입니다. 하단 행은 입력과 동일한 카메라 시점에 표시되는 출력 의미 분할 결과 (포인트에)입니다.
표 5. 입력 feature transform의 효과. 메트릭은 ModelNet40 테스트 세트의 전체 분류 정확도입니다.
그림 6. PointNet 견고성 테스트. 메트릭은 ModelNet40 테스트 세트의 전체 분류 정확도입니다. 왼쪽 : Delete points. 가장 먼 것은 원래 1024 개의 포인트가 가장 먼 샘플링으로 샘플링됨을 의미합니다. 중간 : Insertion. 단위 구에 균일하게 흩어져있는 이상 값. 오른쪽 : perturbation(섭동, 작은 변화). 각 점에 독립적으로 가우스 노이즈를 추가합니다.
그림 7. 임계점 및 상한 모양. 임계점은 주어진 모양에 대한 전역 모양 특징을 공동으로 결정하지만 임계점 집합과 상한 모양 사이에있는 모든 점 구름은 정확히 동일한 특징을 제공합니다. 깊이 정보를 표시하기 위해 모든 그림에 색상을 지정합니다.
표 6. 3D 데이터 분류를위한 심층 아키텍처의 시간 및 공간 복잡성. PointNet (바닐라)은 입력 및 기능 변환이없는 분류 PointNet입니다. FLOP은 부동 소수점 연산을 나타냅니다. "M"은 백만을 의미합니다. 하위 볼륨 및 MVCNN은 여러 회전의 입력 데이터 풀링을 사용했습니다. 또는 보기가 없으면 성능이 훨씬 떨어집니다.




 $$1)\ f(\{x_1,...,x_n\})≈g(h(x_1),...,h(x_n))$$$$2)\ f:2^{R^N}→R,h:R^N→R^K and\ g:R^k×⋯×R^K→R$$
$$1)\ f(\{x_1,...,x_n\})≈g(h(x_1),...,h(x_n))$$$$2)\ f:2^{R^N}→R,h:R^N→R^K and\ g:R^k×⋯×R^K→R$$