Monocular, One-stage, Regression of Multiple 3D People
Abstract
인간 pose detection는 딥 러닝, 매개 변수 인간 모델링, 대규모 2d 및 3d 데이터 세트의 최근 발전으로 큰 혜택을 받았습니다. 그러나 기존 3D 모델은 이미지당 한 사람, 전체 인물 보기, 간단한 배경 또는 많은 카메라를 고려하여 장면에 대해 강력한 가정을 합니다. 본 논문에서는 최첨단 심층 다중 작업 신경망과 매개 변수 인간 및 장면 모델링을 활용하여 상호 작용하는 여러 사람을 위한 fully automatic monocular visual sensing system (완전 자동 단안 시각적 감지 시스템)을 활용하며,
(i) 단일 이미지에서 여러 사람의 2d 및 3d 자세와 모양을 유추하고 양쪽 모에서 세밀한 의미 표현에 의존합니다. 델타 및 이미지 레벨, 피드포워드 및 피드백 구성요소와 결합된 최적화를 안내하기 위해,
(ii) ground plane support and simultaneous volume occupancy (지면 지원 및 여러 사람에 의한 동시 볼륨 점유)를 포함한 장면 제약 조건을 자동으로 통합하며,
(iii) 시간적 사람 할당 문제를 최적으로 해결하고 이미지 정렬 충실도를 유지하면서 일관성 있는 시간적 포즈와 움직임 재구성을 부과하여 단일 이미지 모델을 비디오로 확장합니다.
이 논문에서는 단일 및 다중 사용자 데이터 세트 모두에 대해 실험을 수행하고 모델의 각 구성 요소를 체계적으로 평가하여 향상된 성능과 광범위한 다중 인간 감지 기능을 보여 줍니다. 또한 이 방법을 여러 사람, 심각한 폐색 및 도전적인 자연 장면에서 포착된 다양한 배경이 있는 이미지에 적용하고 좋은 지각 품질의 결과를 얻습니다.
1. Introduction
최근에는 단안 3D 인체 자세 및 형상 추정에 큰 진전이 있었습니다 [5, 9, 18, 20, 21, 40, 43]. 그러나, 더 일반적인 장면으로 발전함에 따라, 다인칭 사례에서 잘림, 사람-인칭 폐색 및 환경 폐색 문제를 다루는 것이 중요합니다. 이러한 폐색에 대한 견고성은 실제 적용에 매우 중요합니다.
기존 접근 방식[13, 20, 44, 45]은 다인 장면을 처리할 수 있는 2D 인체 감지기를 갖춘 다단계 설계를 따릅니다. 일반적으로 이들은 먼저 사람 영역을 탐지한 다음 경계 상자 수준의 특징을 추출합니다. 이 기능은 각 3D 인체 메시를 회귀시키는 데 사용됩니다 [9, 18, 19, 20, 21, 22, 34, 39, 43, 51]. 그러나 그림 1과 같이 이 전략은 다중 사용자 폐색 및 절단 시 실패할 수 있습니다. 구체적으로, 그림 1(b)와 같이, 두 사람이 겹치는 경우, 다중 단계 방법은 유사한 이미지 패치에서 다양한 신체 메시를 추정하기 어렵습니다. 이러한 분리할 수 없는 다중 사용자 사례에서 실패를 초래하는 것은 암시적 경계 상자 수준 표현의 모호성입니다.
다중 사용자 2D 포즈 추정의 경우, 이 문제는 미묘하고 효과적인 상향식 bottom-up 프레임워크를 통해 해결됩니다. 우선 모든 신체 관절을 감지한 후 관절 그룹에 의해 다른 사람들에게 할당하는 것이 패러다임입니다. 그것은 붐비는 장면에서 인상적인 성능을 보장하는 픽셀 레벨 바디 조인트 표현입니다 [6, 7, 35]. 그러나 상향식 1단계 공정을 조인트 이상으로 확장하는 것은 중요합니다 [13]. 수십 개의 신체 관절을 예측하는 2D 포즈 추정과는 달리, 우리는 수천 개의 꼭짓점을 가진 인간의 신체 메시를 회귀해야 하기 때문에 신체 관절 감지와 그룹화의 패러다임을 따르기가 어렵습니다.
본 논문에서는 픽셀당 예측 방식으로 여러 3D 사용자를 회귀시키는 1단계 네트워크인 ROMP를 소개합니다. 전체 이미지에서 여러 개의 차별화 가능한 맵을 직접 추정하여 모든 사람의 3D 메시를 쉽게 구문 분석할 수 있습니다. 특히, 그림 1(c)에 표시된 것처럼, ROMP는 차체 센터의 2D 위치와 해당 3D 차체 메시의 파라미터 벡터를 각각 나타내는 차체 센터 열 지도와 메시 매개 변수 맵을 예측합니다. 간단한 파라미터 샘플링 프로세스를 통해 열 지도에서 설명하는 신체 중심 위치의 Mesh 매개 변수 맵에서 모든 사람의 3D Body Mesh 매개 변수 벡터를 쉽게 추출할 수 있습니다. 그런 다음 SMPL 본문 모델[29]에 샘플 메쉬 파라미터 벡터를 넣어 다중인 3D 메쉬를 도출합니다. 이러한 신체 중심 유도 픽셀 레벨 표현은 배경/교합에서 대상을 명시적으로 가리키며, 이는 다중 사용자 중복 사례에서 효과적인 학습을 촉진합니다. 또한 로컬 뷰에서 학습한 경계 상자 수준 기능과 달리 전체 이미지에서 학습한 종단 간 학습은 모델을 전체적 뷰에서 예측하는 데 익숙하게 만듭니다. 이 순수한 전체론적 관점은 실제 영역에 정확히 맞으며, 보이지 않는/야생적인 장면에서 모델의 일반화와 견고성을 보장합니다.
또한, 심각한 중복 사람들의 신체 중심이 동일한 2D 위치에서 충돌할 수 있다는 점을 고려하여, 우리는 신체 중심 유도 표현을 고급 버전인 충돌 인식 표현(CAR)으로 더욱 발전시킵니다. 핵심 아이디어는 가까운 신체 중심은 상호 거부반응에 의해 분리되는 양전하와 유사한 신체 중심부의 반발 필드를 구축하는 것입니다. 이렇게 하면, 겹치는 사람들의 신체 중심부가 더 잘 구별될 수 있을 것입니다. 특히 오버랩이 심할 때는 인체 대부분이 보이지 않습니다. 상호 거부반응은 중심을 보이는 신체 부위로 밀어넣어 모델이 보이는 신체 부위의 중심 위치에서 추정된 3D 망사 파라미터를 표본으로 추출하는 경향이 있도록 합니다. 그것은 사람들 사이의 심한 혼탁 속에서 견고성을 향상시킵니다.
다인[13, 44, 45] 및 1인[20, 21, 46] 3D 메쉬 회귀 분석에서의 이전의 최첨단(SOTA) 방법과 비교하여 ROMP는 3DPW[41], CMU Panoptic [16], 3DOH50K[46]를 비롯한 까다로운 벤치마크에서 우수한 성능을 달성합니다. 개인별 폐색 데이터 세트(Crowdpose [25] 및 3DPW-PC, 개인별 폐색 하위 집합 [41])에 대한 실험은 개인별 폐색에서 제안된 CAR의 효과를 입증합니다. 일반적인 경우에 그것을 더 평가하기 위해, 우리는 인터넷과 웹 카메라 비디오에서 ROMP를 테스트합니다. 다단계 경쟁업체의 백본과 동일한 백본을 가진 ROMP는 하나의 1070Ti GPU에서 30FPS 이상의 실시간 성능을 달성합니다.
요약하면 기여도는 다음과 같습니다.
- 단안 다인 3D 망사 회귀 분석을 위해 간단하면서도 효과적인 1단계 회귀 네트워크인 ROMP가 제안됩니다.
- 제안된 명시적 차체 중심 유도 표현은 픽셀 수준의 휴먼 메시 회귀를 종단 간 방식으로 촉진합니다.
- 심각한 중복 사례를 처리하기 위해 충돌 인식 표현을 개발합니다.
- ROMP는 정확성과 효율성 면에서 이전의 SOTA 방법을 능가합니다. 단안 영상에서 다중 사용자 3D 망사 회귀를 위한 최초의 오픈 소스 실시간 방법입니다.
3.1 Multiple Persons in the Scene Model
Problem formulation - 일반성의 손실 없이NfN_f 프레임이 있는 비디오에서NpN_p가 고유하게 탐지된 사람을 고려합니다. 우리의 목적은 최상의 포즈 상태 변수 $θ = [θ_p^f] ∈ R^{N_p × N_f × 72},$ 형상 모수 $B = [B_p^f] ∈ R^{N_p × N_f × 10}$ 및 개별 개인 변환 $T = [t^f_p] ∈ R^{N_P × N_f × 3}$ 을 유추하는 것입니다. 먼저 프레임당, 사람 중심의 목표 함수 $L^{p,f}_I(B, Ω, T)$ 를 작성하는 것으로 시작합니다.
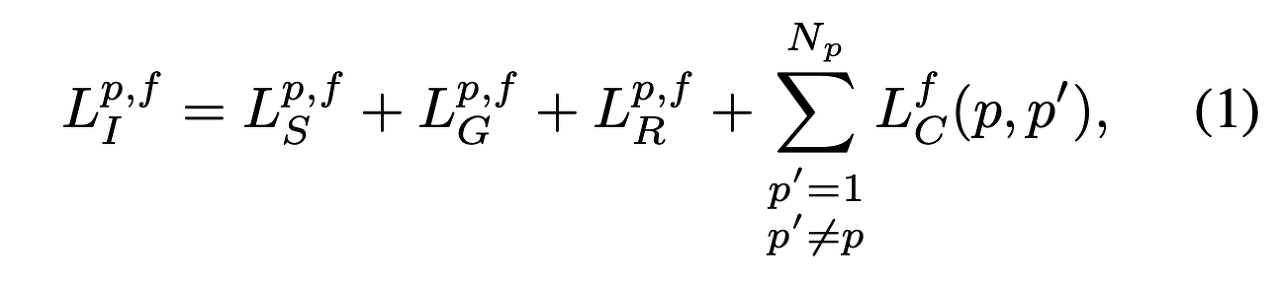
LS가 모든 프레임에서 계산된 시각적 증거를 의미 본체 부분 라벨링의 형태로 고려하는 비용, LC는 장면에서 서로 다른 사람들 사이의 동시(3d) 볼륨 점유에 불이익을 주며, LG는 장면의 일부 사람들이 공통 지원 평면을 가질 수 있다는 제약을 통합합니다. 용어 $L^{p,f}_R=L^{p,f}_R(θ)$ 는 [2]와 유사한 가우스 혼합물입니다. 모든 제약 조건 하에서 여러 사람의 image cost는 다음과 같이 쓸 수 있습니다.
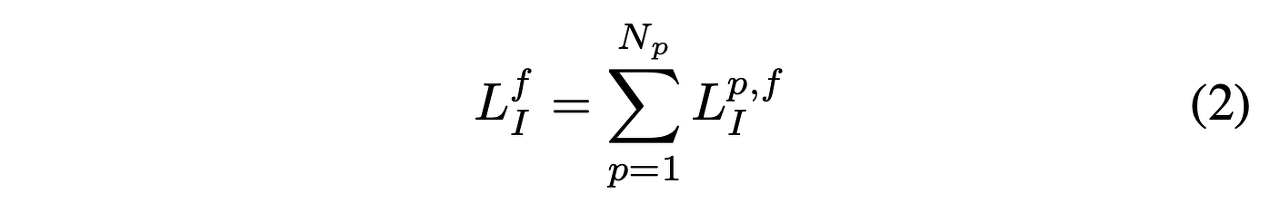
단안 비디오를 사용할 수 있는 경우 정적 비용 Lf는 전체 비디오에서 시간적 할당이 해결되면 각 사람에게 적용할 수 있는 궤적 모델로 증가합니다. 전체 비디오 손실은 쓰입니다.
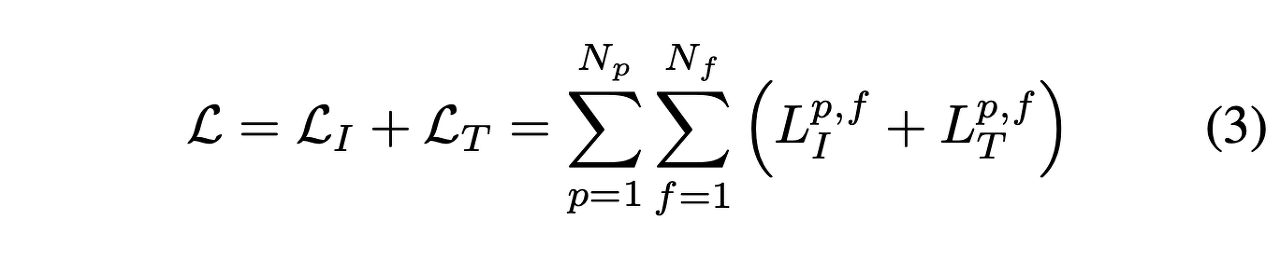
여기서 LT는 부드러움, 일정한 속도 또는 가속도에 대한 가정, 또는 인간 모션 캡처 데이터에서 학습한 보다 정교한 모델 등 인간의 움직임에 대한 사전 지식을 통합할 수 있습니다. 다음 섹션에서는 각 비용 기능에 대해 자세히 설명합니다.1
여러 사람의 자세와 3d 위치를 추론하기 위해 우리는 인간 감지를 위한 최첨단 심층 멀티태스킹 신경망인DMHS[23]를 가진 매개 변수 인간 표현인 SMPL[15]에 의존합니다. 실제로, 우리는 비디오 전체에 걸쳐 일정한 수의 사람을 추정할 수 없으며 먼저 LS와 LC라는 처음 두 비용 함수의 합을 최소화하여 각 프레임에 대해 독립적으로 B,Ω, T 매개 변수를 추론한 다음, 할당 문제를 최적으로 해결하기 위해 각 프레임에서 얻은 사람을 일시적으로 추적한 다음 다시 최적화합니다. 그런 다음, 우리는 할당 문제를 최적으로 해결하기 위해 각 프레임에서 얻은 사람을 일시적으로 추적한 다음 시간적 및 지상 평면 제약 조건, LT 및 LG를 추가하여 목표를 다시 최적화합니다. 일부 프레임에서만 탐지된 사용자의 경우 해당 부분 집합에 대해 최적화 작업이 진행됩니다. 방법에 대한 개요는 그림 2에 나와 있습니다.

- 그림 2: 여러 사람의 3D 자세와 체형을 추정하기 위한 단안 모델의 처리 파이프라인입니다. 시스템은 피드포워드 초기화 및 의미 피드백을 통합한 단일 사용자 모델을 지상 평면 추정, 상호 볼륨 제외 및 장면의 모든 사람에 대한 공동 추론과 같은 추가 제약 조건과 결합합니다. 단안 비디오의 경우, 사람들의 3D 시간 할당은 헝가리 방법을 사용하여 해결되며, 이미지 일관성을 포함한 모든 제약 조건에서 궤적 최적화trajectory optimization는 모든 사람과 시간 단계에 걸쳐 공동으로 수행되어 최적의 결과를 얻을 수 있습니다.
3.1. Single Person Feedforward-Feedback Model
SMPL [15]는 템플릿 꼭짓점 V0으로 표현되고 포즈 벡터 $θ ∈ R^{1×72}$ 와 형상 모수 $β ∈ R^{1×10}$ 으로 제어되는 차별화 가능한 매개 변수 인간 모델입니다. 모델의 포즈는 본체 관절이 있는 표준 골격 rig(skeletal rig)에 의해 정의됩니다. 각 신체 부위에 대해 포즈를 제어하는 벡터는 키네마틱 트리에서 부모의 상대 회전 w.r.t의 축 각도 표현으로 제공됩니다. 모든 조인트의 축 각도는 Rodrigues 변환을 사용하여 회전 행렬로 변환됩니다. 형상 모수는 사지 크기, 높이 및 무게에 영향을 미치며 등록된 메시에서 학습한 저차원 형상 공간의 계수를 나타냅니다. SMPL은 and와 ,에 의존하는 행렬 함수, 즉 V(θ, ||V0) r RVn_V×3과 연결된 키네마틱 트리의 관절 위치를 출력하는 J(,, β|V0) rRnJ×3를 제공합니다. SMPL 모델의 총 정점 수는 nV = 6890이고 키네마틱 트리의 총 이음매 수는 nJ = 24입니다. 설명의 단순성을 위해 v는 V(β, 0|V0)를 나타내고 x는 J(β, v|V0)로 합니다. 우리는 카메라 공간에서의 모델의 번역을 t r R1×3이라고 부릅니다.
4.4. Discussion
성능 향상의 출처를 확인하기 위해 서로 다른 장면이 포함된 3DPW 하위 집합에 대한 절제 연구를 수행합니다. 표 5의 SOTA 방법[13, 20]과 비교했을 때, 우리의 주요 이점은 사람이 개입한 경우와 비개입/단절된 경우에서 나타납니다. 이러한 결과는 제안된 픽셀 수준 표현이 사람-인격 폐색 및 절단 사례에 대한 보다 효과적인 학습을 촉진할 수 있음을 보여줍니다. 또한 4.2절에 소개된 것처럼, ROMP는 미세 조정 없이 여러 벤치마크에서 우수한 결과를 달성하며, 이는 다양한 실제 장면에서 우리의 견고성과 일반화를 보여줍니다. 실험에서 변수(예: 백본, 훈련 설정 등)를 제어함으로써 ROMP와 SOTA 방법[13, 20, 21] 사이의 차이를 표현 학습 방식으로 좁힙니다. ROMP는 전체론적 보기에서 픽셀 수준 표현을 학습하는 반면, 다단계 SOTA 방법은 로컬 보기에서 경계 상자 수준 표현을 학습합니다. 강력한 신체 센터의 지침을 제외하고, 우리의 완전한 컨볼루션 설계는 더 나은 일반화를 위해 중요한 경계 상자 외부의 풍부한 장애에 대해 더 차별적인 특징을 학습하도록 ROMP를 촉진합니다.
5. 결론
우리는 단안 다인 3D 망사 회귀를 위한 새로운 1단계 네트워크 ROMP를 도입합니다. 픽셀 수준 추정을 위해, 우리는 명시적인 차체 중심 유도 표현을 제안하고 이를 충돌 인식 버전인 CAR로 더욱 개발하여 사람-인격 폐색 시 강력한 예측을 가능하게 합니다. ROMP는 실시간 추론 속도뿐만 아니라 여러 벤치마크에서 SOTA 성능을 달성하는 최초의 오픈 소스 1단계 방법입니다. 커뮤니티에서 ROMP는 깊이 추정, 추적 및 상호 작용 모델링과 같은 관련 다중 사용자 3D 작업을 위한 단순하면서도 효과적인 기준선이 될 수 있습니다.