
- 그림 1: raw 비디오에서 시각적 대응에 대한 representation을 배울 것을 제안합니다. 획득한 representation은 미세 조정 없이 시각적 대응과 관련된 다양한 작업으로 일반화되어 (a) 다중 인스턴스 마스크, (b) 포즈, (c) 시맨틱 마스크, (d) 장거리 optical flow, (e) 텍스처를 propagate.
Abstract
레이블이 지정되지 않은 비디오에서 시각적 대응을 학습하기 위한 self-supervised 방법. 주요 아이디어는 시각 representation을 처음부터 학습하기 위한 free supervisory signal로 시간에 따른 주기 일관성을 사용 Train 시 모델은 cycle-consistent tracking 을 수행하는 데 유용한 feature map representation을 학습합니다. 테스트 시 획득한 representation을 사용하여 시공간을 가로질러 nearest neighbors 을 찾습니다. 우리는 비디오 객체 세분화, 키포인트 추적 및 optical flow을 포함한 다양한 시각적 대응 작업에 걸쳐 미세 조정 없이 representation의 일반화 가능성을 입증합니다.
1. Motivation
젊은 대학원생이 타케오 카나데에게 컴퓨터 비전에서 가장 중요한 세 가지 문제가 무엇인지 물었을 때, 카나데는 이렇게 대답했습니다: "Correspondence Correspondence Correspondence!" 실제로 optical flow 및 추적에서 동작 인식 및 3D 재구성에 이르는 대부분의 근본적인 시력 문제는 시각적 Correspondence의 개념을 다시 필요로 합니다. Correspondence는 서로 다른 시각적 지각을 지속적인 실체로 연결하고 공간과 시간의 시각적 추론에 기초를 두는 접착제 역할을 함.
픽셀 단위에서 객체 레벨에 이르기까지 시각적 correspondence에 대한 representation은 주로 라벨링된 데이터가 많이 필요한 지도 학습 접근 방식을 사용하여 광범위하게 연구되어 왔습니다. optical flow과 같은 낮은 수준의 correspondence을 학습하기 위해 합성 컴퓨터 그래픽 데이터는 종종 supervision으로 사용됩니다. 이는 annotation이 많이 들어간 데이터에 기반하는데 본 연구에서 인간의 감독 없이 다양한 수준의 시각적 대응(그림 1)에서 추론을 지원하는 representation을 배웁니다. free supervision의 비옥한 원천은 비디오입니다. 세계는 갑자기 변하지 않기 때문에, 시간에 인접한 관측치 사이에는 시각적 대응이 내재되어 있습니다. 문제는 어떻게 이러한 correspondences들을 찾고 학습 신호로 바꾸느냐 하는 것입니다.
고정식 카메라가 주로 사용하는 정적인 세계에서는 어떤 것도 움직이지 않고 시각적 불변성(날씨, 조명)을 포착하는 것이 지도 메트릭 학습에 해당하기 때문에 correspondences 이 간단합니다. 그러나 dynamic 세계에서는 공간에서의 움직임으로 인해 외모의 변화가 혼란스러워집니다. 시각적 불변성을 캡처하려면 추적 학습이 필요하지만, 추적은 시각적 불변성의 모델에 의존하기 때문에 대응성을 찾는 것이 더 어려워집니다. 본 논문은 두 가지 작업을 동시에 수행하는 방법을 self-supervised 방식으로 학습할 것을 제안합니다.

- 그림 2: A Cycle in Time. 비디오가 주어진 경우, 시간 내 사이클에 의해 형성된 시퀀스를 따라 추적하는 것은 self supervised될 수 있습니다. target은 사이클의 시작일 뿐입니다. 시작과 끝 사이의 노란색 화살표는 미분 가능한 학습 signal.
핵심 아이디어는 역방향으로 추적하고(즉, 시간 내 주기를 따라) 시작점과 끝점 사이의 불일치를 손실 함수로 사용함으로써 대응에 대한 unlimited supervision을 얻을 수 있다는 것입니다(그림 2). 학습된 deep feature space에서 템플릿 매칭에 의한 추적을 수행합니다. 손실을 최소화하려면(즉, cycle-consistent을 유지하기 위해) 모델은 프레임 간의 identifying correspondences을 지원하는 feature representation을 학습해야 합니다. 이러한 feature가 개선됨에 따라, 모델을 cycle-consistent으로 유도하면서 객체를 추적할 수 있게 됩니다. 따라서 이러한 feature space에서 체인 correspondences에 대한 학습은 시간 내 local transformations에 대한 시각적 유사성 메트릭을 산출해야 하며, 이 메트릭은 test 시 correspondences에 대한 독립형 거리 메트릭으로 사용할 수 있습니다.
개념적으로는 간단하지만, cycle-consistent을 기반으로 목표를 구현하는 것은 어려울 수 있습니다. 추가적인 제약 없이, 학습은 지름길을 택할 수 있고, correspondences은 cycle-consistent이지만 잘못될 수 있습니다. 우리의 경우, 절대 움직이지 않는 것에대한 track은 본질적으로 cycle-consistent합니다. 트래커가 각 연속적인 프레임에서 다음 패치를 다시 배치하도록 함으로써 이러한 문제를 방지합니다. 또한 개체 포즈의 occlusion이나 갑작스러운 변화로 인해 cycle-consistent을 달성할 수 없을 수 있습니다. 그림 3(오른쪽)과 같이 스킵 사이클로 프레임을 건너뛰어 주기 일관성을 유지할 수 있습니다. 대체로 train 초기에 correspondence이 부족할 수 있으며, 그림 3(왼쪽)과 같이 주기가 짧으면 학습이 쉬워질 수 있습니다. 따라서, 우리는 다양한 사이클에서 동시에 학습하여 자연스러운 커리큘럼을 만들고 더 나은 훈련 데이터를 제공합니다.
제안된 공식은 raw 비디오에서 시각적 대응에 대한 representation을 학습하기 위한 일반적인 프레임워크를 제공하여 서로 다른 모든 미분 가능한 추적 작업과 함께 사용될 수 있습니다. 이 방법은 인간의 표기법에 의존하지 않기 때문에 온라인에서 사용할 수 있는 거의 무한대에 가까운 비디오 데이터를 통해 학습할 수 있습니다. 우리는 pose, keypoint, and segmentation propagation (of objects and parts) to optical flow에 이르기까지 다양한 수준의 시각적 대응에서 작업에 대해 학습된 features의 유용성을 입증합니다.

- 그림 3: Multiple Cycles and Skip Cycles. 개체 포즈의 sudden changes in object pose or occlusions 때문에 주기 일관성을 달성하지 못할 수 있습니다. 서로 다른 길이의 여러 사이클을 동시에 최적화해 해결할 수 있습니다. full cycle이 너무 어려울 때(왼쪽) 짧은 사이클을 통해 학습할 수 있습니다. 이렇게 프레임을 건너뛰는 사이클도 가능하며, 이는 momentary occlusions(오른쪽)을 처리할 수 있습니다.
2. Related Work
3. Approach

- Figure 4: Method Overview. (a) training, the model learns a feature space encoded by φ to perform tracking using tracker T . By tracking backward and then forward, we can use cycle-consistency to supervise learning of φ. only the initial patch pt is explicitly encoded by φ; other patch features along the cycle are obtained by localizing image features. (b) We show one step of tracking back in time from t to t − 1.
- Given input image features $x^I_{t−1}$ and query patch features $x^p_t$ , T localizes the patch $x^p_{t−1}$ in $x^I_{t−1}$. This is performed iteratively to track along the cycle in (a).
목표는 이미지에서 추출한 패치 pt를 역방향으로 추적한 후 feature space φ을 학습하는 동시에 cycle-consistency loss lθ(노란색 화살표)을 최소화하는 것입니다. φ의 학습: 현재 패치와 target 이미지의 feature를 입력으로 사용하는 간단한 추적 작업 T에 의존하며, 가장 유사한 이미지 feature region을 리턴합니다. 우리의 T 구현은 그림 4b에 나와 있습니다. 패치가 어디서 왔는지에 대한 정보가 없으면 T는 다음 패치를 로컬라이징하기 위해 φ에 의해 인코딩된 feature과 일치해야 합니다. 그림 4a와 같이, T는 임의로 긴 사이클을 따라 추적하기 위해 시간 경과를 반복하여 적용할 수 있습니다. cycle-consistency loss lθ: 초기 패치 pt의 공간 좌표와 사이클의 끝 I_t 의 패치 사이의 유클리드 거리입니다. lθ 를 최소화하기 위해서, 모델은 사이클을 따라 패치들 사이의 시각적 유사성을 강력하게 측정할 수 있는 feature space φ를 배워야 합니다.
T는 train 용으로만 사용되며 의도적으로 약하게 설계되어 φ에 representation의 부담을 줍니다. test 시에 학습된 φ는 correspondence 문제의 계산에 직접 사용됩니다. 다음에서는 먼저 주기 일치 추적 손실 함수를 공식화한 후 mid-level correspondence 을 위한 아키텍처를 설명합니다
3.1. Cycle-Consistency Losses
우리는 cycle-consistent tracking의 공식화를 설명하고 그것을 사용하여 temporal cycle-consistent을 기반으로 손실 함수를 간결하게 표현합니다.
3.1.1 Recurrent Tracking Formulation
일련의 비디오 프레임 $I_{t-k:t}$ 와 $I_t$에서 가져온 패치 $tp_t$를 입력으로 간주합니다. 이러한 픽셀 입력은 $x^I_{t-k:t} = φ(I_{t-k:t})$ 및 $x^p_t =φ(p_t)$ 와 같은 인코더 φ에 의해 feature space에 매핑됩니다.
T를 미분 가능한 연산 $x^I_s \times x^p_t \mapsto x^p_s$ 로 합니다. 여기서 s와 t는 시간 단계를 나타냅니다. T의 역할은 $x^p_t$와 가장 유사한 이미지 feature $x^I_s$에서 패치 feature $x^p_s$를 로컬라이징하는 것입니다. T를 앞으로 t−i to t−1에서 반복적으로 적용할 수 있습니다.
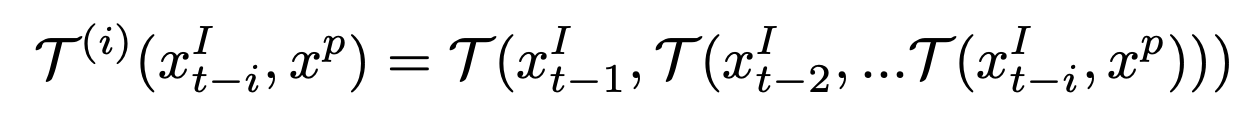
By convention, the tracker T can be applied backwards i times from time t−1 to t−i:
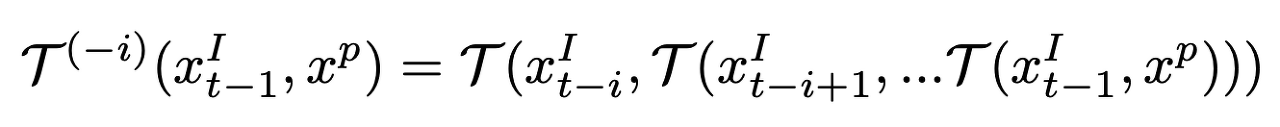
3.1.2 Learning Objectives
다음 학습 목표는 초기 패치와 relocalized 패치(섹션 3.2에 정의됨) 사이의 합의 $l_θ (x^p_t , \hat{x}^p_t )$ 측정에 의존합니다.
Tracking - cycle-consistent loss $L^i_{long}$은 다음과 같이 정의됩니다.

Tracker는 그림 4a에 표시된 것처럼 features을 뒤로 따라가 i steps를 forward하여 초기 쿼리로 재도착합니다.
Skip Cycle - 연속된 프레임을 통한 사이클뿐만 아니라 시간 경과를 건너뛸 수도 있습니다. two-step skip-cycle에서 손실을 $L^i_{skip}$으로 정의합니다.

i 개 step을 skip 해서 longer-range matching을 시도합니다.
Feature Similarity - feature space에서 쿼리 패치 $x^p_t$와 로컬 패치 T(xIt-i, xpt )가 유사해야 합니다. 이 loss은 spatial feature tensors 사이의 negative Frobenius 내부 생성물에 해당합니다.

전체 learning objective 합계는 가능한 k 사이클에 걸쳐 있으며, weight는 λ = 0.1입니다.

3.2. Architecture for Mid-level Correspondence
따라서 설명된 학습 목표를 사용하여 임의의 differentiable tracking models을 train할 수 있습니다.실제로 인코더의 아키텍처는 획득한 representation에 의해 포착된 correspondence의 유형을 결정합니다. 본 연구에서는 mid-level temporal correspondence에 관심이 있습니다. 따라서, 우리는 pixel space보다 크지만 localization가 필요한 작업을 지원할 수 있는 충분한 공간 해상도를 가진 중간 수준의 심층 피처 맵으로 representation을 선택합니다. 개요는 그림 4b에 나와 있습니다.
3.2.1 Spatial Feature Encoder φ
- ResNet-50 architecture [18] without res5 (the final 3 residual blocks).
- 더 큰 spatial outputs을 위해 res4의 공간 stride을 낮춥니다.
- input 프레임은 240 × 240 픽셀로 비디오 프레임에서 임의로 잘라내어 min(H, W ) = 256.
- spatial feature of the frame - 30 x 30
- Image patch 80 x 80 randomly cropped from the full 240 × 240 frame ⇒ feature is 10 × 10
- cosine similarity 계산을 용이하게 하기 위해 spatial features의 채널 차원에서 L2 normalization.
3.2.2 Differentiable Tracker T
인코더의 representation을 고려할 때, 우리는 T로 추적을 수행합니다. 그림 4b에 표시된 것처럼, differentiable tracker는 세 가지 주요 구성 요소로 구성됩니다.
Affinity function f - 에서는 spatial feature $x^I$와 $x^p$의 좌표 간의 유사성을 측정합니다. $f : R^{c×30×30}×R^{c×10×10} → R^{900×100}$과 같이 affinity 함수를 $f(x^I,x^p) : = A$로 나타냅니다. affinity 계산을 위한 일반적인 선택은 임베딩 사이의 내적이며, 최근 문헌에서는 attention[67, 72]으로 언급되었으며, 더 역사적으로 정규화된 cross-correlation[10, 35]로 알려져 있습니다. $x^I$ feature의 spatial grid j는 $x^I{(j)}$이고 $x^p$의 그리드 i는 $x^p(i)$입니다.

여기서 similarity A(j, i)는 각 xp(i)에 대해 xI의 공간 치수에 대한 softmax에 의해 정규화됩니다. affinity function는 모든 feature dimension에 대해 정의됩니다.
Localizer g - 선호도 행렬 A를 입력으로 사용하여 xp와 가장 일치하는 xI의 패치에 해당하는 localization parameters θ를 추정합니다. g는 두 개의 컨볼루션 레이어와 하나의 선형 레이어로 구성됩니다. $g : R^{900×100} → R^3$인 경우 2D 변환 및 회전에 해당하는 이중선 샘플링 그리드에 대해 3개의 파라미터를 출력하도록 제한했습니다. g의 표현식은 인코더에 representation 부담을 주기 위해 의도적으로 제한됩니다.
Bilinear Sampler h - g에 의해 예측된 이미지 특징 xI와 predicted를 사용하여 xp와 동일한 크기의 새로운 패치 feature h(xI, ))를 생성하기 위함. h : Rc×30×30 × R3 →− Rc×10×10.
3.2.3 End-to-end Joint Training
encoder φ and T의 구성은 의 엔드 투 엔드 훈련을 가능하게 하는 패치 트래커를 형성합니다.

Alignment Objective $l_θ$ cycle-consistent losses Lilong과 Liskip에 적용되어 두 패치 간의 align error를 측정합니다. [53]에서 소개한 공식을 따릅니다. $M (θ_{x^p} )$이 image feature xI에서 패치 feature xp를 형성하는 데 사용되는 bilinear sampling grids라 하면 $M (θ_{x^p} )$에 n개의 샘플링 좌표가 포함되어 있다고 가정할때 alignment objective는 다음과 같이 정의됩니다.

4. Experiments
- VLOG 데이터 세트[12]에 대해 처음부터 학습된 모델에 대한 실험 결과를 보고하며,
- 키네틱스 같은 다른 대규모 비디오 데이터 세트 train
- DAVIS-2017 [48], JHMDB [26] 및 VIP(비디오 인스턴스 레벨 구문 분석) [85]와 같은 몇 가지 까다로운 비디오 프로포테이션 작업에 대한 without fine-tuning 평가.
4.1. Common Setup and Baselines
Training. annotations or pre-training 없이 VLOG 데이터 세트[12]에서 train. VLOG 데이터 세트에는 114K 비디오가 포함되어 있으며 전체 비디오 길이는 344시간입니다. 교육 중에는 과거 프레임 수를 k = 4. 우리는 32개의 클립(GPU당 8개의 클립) 크기의 4-GPU 기계에서 30세대에 걸쳐 훈련합니다. 이 모델은 Adam의 learning rate 0.0002 및 모멘텀 β1 = 0.5, β2 = 0.999로 최적화되었습니다.
Inference. 테스트 시 훈련된 인코더 representation을 사용하여 비디오 propagation를 위한 dense correspondences을 계산합니다. 첫 번째 프레임의 초기 라벨이 주어지면 비디오의 나머지 프레임에 라벨을 적용합니다. 각 작업의 첫 번째 프레임에 대해 지정된 대상에 의해 Label이 제공됩니다. (DAVIS-2017, JHMDB, instance-level and semantic-level masks for VIP.) 각 픽셀의 라벨은 C 클래스로 이산화됩니다. 세그멘테이션 마스크의 경우 C는 인스턴스 또는 semantic 레이블의 수, 키포인트의 경우 C는 키포인트 수입니다. 백그라운드 클래스가 포함되어 있습니다. spatial feature에 레이블을 전파합니다. 첫 번째 프레임의 라벨은 one-hot vectors이고 propagated 라벨은 soft distributions입니다.
Propagation by k-NN. - Given a frame It and a frame It−1 with labels, feature space에서 affinity 계산 (Eq. 1). label yi of pixel i in $I_t$ as
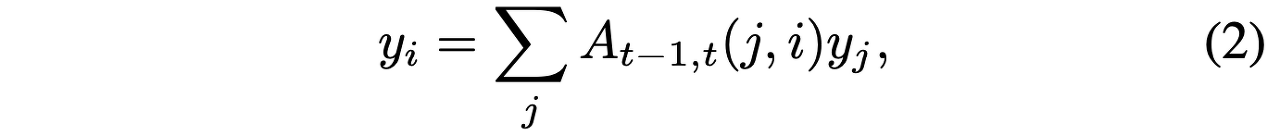
- $A_{t−1,t} (j, i)$ - affinity between pixels i in It and j in It−1.
- 각 픽셀 i에 대해 가장 높은 affinity At-1,t(j,i)로 상위 5픽셀부터 propagate. 레이블은 I1뿐만 아니라 $I_{1:t-K}$에서 프로파게이팅되고 평균화됩니다. 마지막으로 이미지 크기에 맞게 레이블 맵을 상향 샘플링합니다. 세그먼트화의 경우 각 픽셀의 클래스 분포의 argmax를 사용합니다. 키포인트의 경우 각 키포인트 유형에 대해 최고 점수가 있는 픽셀을 선택합니다.
Baselines. 비교 1. Identity 2. Optical Flow (FlowNet2 [22]) 3. SIFT Flow [39] ...
5. Limitations and Future Work
원칙적으로 우리의 방법은 더 많은 데이터로 계속 개선되어야 하지만, 실제로 학습은 적당한 양의 훈련(예: 30개 시대) 후에 안정되는 것처럼 보입니다. 따라서 다음 단계는 더 크고 노이즈가 많은 데이터로 더 잘 확장하는 방법입니다. 예를 들어, 교육 시 주기를 찾기 위해 더 나은 검색 전략을 사용하여 조직 결함에 대한 견고성과 부분적인 관찰성을 향상시키는 것이 중요한 요소입니다. 또 다른 문제는 훈련 시간에 무엇을 추적할 것인지 결정하는 것입니다. 패치를 무작위로 선택하면 배경 패치 위치 확인 및 모호성 추적과 같은 문제가 발생할 수 있습니다. 예를 들어, 두 개의 개체가 포함된 패치를 추적하려면 어떻게 해야 할까요? 추적할 대상을 공동으로 학습하면 감독되지 않은 물체 탐지가 발생할 수도 있습니다. 마지막으로, 훈련과 시험 시간 모두를 추적하기 위한 더 많은 컨텍스트를 통합하는 것은 공간-시간적 대응의 보다 표현력 있는 모델을 학습하는 데 중요할 수 있습니다. 우리는 이 연구가 raw 비디오에 내재된 풍부한 시각적 대응으로부터 확장 가능하고 엔드 투 엔드 방식으로 배우는 단계로 나아가기를 희망합니다. 우리의 실험은 특정 수준의 대응에서 유망한 결과를 보여주지만, 전체 스펙트럼을 다루기 위한 많은 작업이 남아 있습니다.




댓글