728x90
반응형
1. Abstract & Introduction
- CLIP, ALIGN 이후 Large web scale 데이터로 VLP 모델을 학습시키기 시작.
- 두가지 문제 존재
- 데이터 관점 : Large web scale data 특성상 image와 text 데이터에 noise가 많다는 한계점이 존재.
- → 잘못된 캡션을 걸러내고, 새로운 캡션을 사용하여 데이터 셋을 bootstrapping하는 CapFilt 구조를 제시하여 위의 한계점을 극복.
- 모델 관점 : 구조적 한계 때문에 특정 task(Image understanding, Text generation 등)에만 강력.
- 구조적 한계
- 대부분이 인코더-디코더 모델
- 인코더 기반 모델은 텍스트 생성 작업(예: 이미지 캡션)에 적용하기가 쉽지 않음
- 인코더-디코더 모델은 이미지-텍스트 검색 작업에 성공적으로 채택되지 않음
- 구조적 한계
- → BLIP은 새로운 모델 구조인 MED (Multimodal mixture of Encoder-Decoder)를 통해 강한 일반화 성능을 보이는 VLP 모델을 선보이며 다양한 VL task에서 SOTA 달성.
- 제안
- Multimodal mixture of Encoder-Decoder (MED) : multi-task pretrain / transfer learning
- unimodal encoder / image-grounded text encoder / image-grounded text decoder로 사용 가능.
- image-text contrastive learning / image-text matching / image- conditioned language modeling이라는 세 가지 objective로 joint pretrain.
- Captioning and Filtering (CapFilt) : noisy 이미지-텍스트 쌍을 학습하기 위한 새로운 dataset bootstraping 방식.
- Pretrain된 MED를 캡션을 생성하는 captioner와 원본 웹 텍스트와 합성 텍스트 모두에서 노이즈가 있는 캡션을 제거하는 Filter의 두 가지 모듈로 세분화하여 finetune.
- Multimodal mixture of Encoder-Decoder (MED) : multi-task pretrain / transfer learning
2. Related Work
2.1. Vision-language Pre-training
2.2. Knowledge Distillation
2.3. Data Augmentation
3. Method
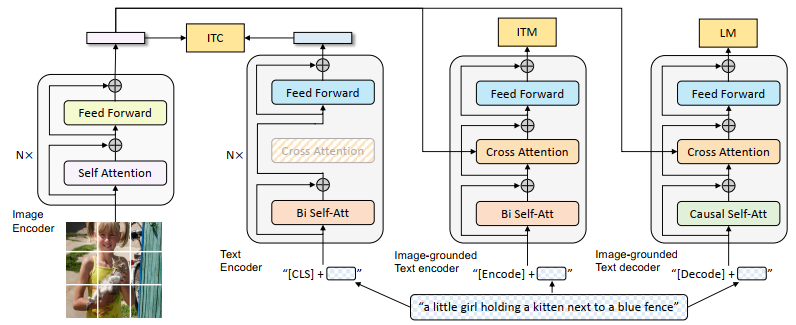
3.1. Model Architecture
- Image, text 데이터를 encoder (ViT, BERT 등)로 인코딩하고, task에 맞는 Loss 함수를 활용.
ViT사용- 이미지를 패치로 나누어 일련의 임베딩으로 인코딩 & 글로벌 이미지 feature를 위한 [CLS] 토큰 추가.
- Pretrained OD 사용하는 것과 비교하면, ViT를 사용하는 것이 더 계산 친화적이며 최근 채택 연구 증가.
- Understanding / Generation 가능한 통합 모델을 사전 학습하기 위해 MED 제안 (아래 세가지 기능 가능)
- Unimodal encoder 이미지와 텍스트를 별도로 인코딩.
- 텍스트 인코더는 입력의 시작 부분에 [CLS] 토큰을 추가하여 문장을 요약하는
BERT와 동일.
- 텍스트 인코더는 입력의 시작 부분에 [CLS] 토큰을 추가하여 문장을 요약하는
- Image-grounded text encoder
- 텍스트 인코더의 각 트랜스포머 블록에 대해 Self attn layer 와 FFN 사이에 Cross attn layer를 삽입하여 visual 정보를 주입.
- Task-specific [Encode] token이 텍스트에 추가되고, [인코딩]의 출력 임베딩이 이미지-텍스트 쌍의 멀티모달 표현으로 사용됩니다.
- Image-grounded text decoder
- image-grounded text encoder의 bi-directional self-attention layer를 causal self-attention layers로 대체
- [Decode] token 시퀀스의 시작을, end-of-sequence token 시퀀스의 끝을 알림.
- Unimodal encoder 이미지와 텍스트를 별도로 인코딩.
3.2. Pretraining Objectives
- ITC, ITM, LM 세 가지 objective joint optimize
- 각 이미지-텍스트 쌍은 계산량이 많은 ViT 한 번만 / text transformer 세 번 통과
- ITC(Image-Text Contrastive Loss):
- Unimodal 목표 Contrastive Learning
- 같은 {image, text} pair에 있으면 코사인 유사도가 높게, 반대면 유사도가 낮게 나오도록 학습.
- → Ex) 한 batch에 16개의 데이터가 있다고 가정하면, 하나의 이미지는 자신과 매칭된 한 개의 text와만 positive pair 관계에 있고, 나머지 15개의 text에 대해 negative pair가 되도록 학습.
- Noisy web 데이터의 특성상, 잘못된 정보가 많으므로 momentum encoder를 사용해서 pseudo-label을 생성하여 negative pair 내의 potential positive 학습.
- → 이미지를 더 풍성하고 정확한 의미를 가진 캡션과 연결.
- ITM(Image-Text Matching Loss):
- image-grounded text encoder 학습 / binary classification task
- {image, text} 쌍이 match 됐는지 예측하도록 학습.
- LM과 마찬가지로 이미지 정보를 text와 Cross-Attention.
- 학습 과정에서 negative sample을 선택할 때, 최대한 image나 text와 semantic 정보가 비슷한 hard negative sample을 선택해 학습.
- LM(Language Modeling Loss):
- image를 보고 text를 생성할 수 있도록 학습.
- Image encoder를 거쳐서 나온 이미지 정보를 Cross-Attention 연산을 통해 받아서 해당 이미지에 대한 캡션을 생성.
- MLM loss과 비교하여, LM은 visual information를 일관된 캡션으로 변환 가능하게 해줌.
- 효율을 위해 text encoder 와 text decoder는 SA layer를 제외하고 모든 파라미터 공유 / SA가 인코딩 디코딩 작업의 차이를 가장 잘 이해한다고 설명함.
- 인코더 : 현재 인풋 토큰의 표현 생성을 위해 bi-directional self-attention 사용
- 디코더 : 다음 토큰 예측을 위해 causal self-attention 사용
3.3. CapFlit
- annotation 비용 너무 큼. web data는 많지만 noisy.
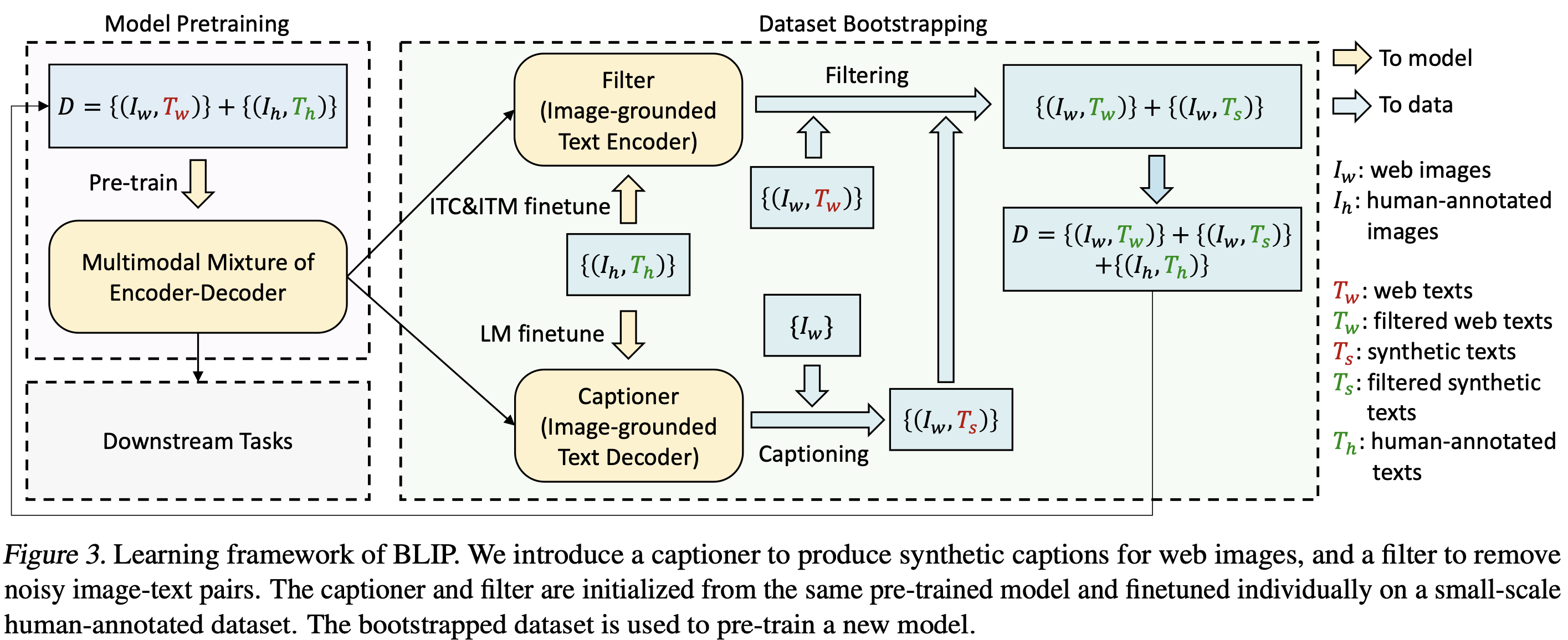
- text corpus 개선.
- 인간이 직접 제작한 {image, text} pair로 Filter(image-grounded Text Encoder) 학습하고, web에서 수집한 {image, text} pair, 그리고 Captioner(image-grounded text decoder)로 생성한 {image, generated_text} pair를 각각 Filter(image-grounded text encoder)에 통과. 이 때, image, text가 서로 안 맞는 경우를 제거하는 방식으로 Noisy web data 문제를 해결.
- 모두 사전 학습된 동일한 MED 모델에서 초기화되고 COCO dataset으로 각각 finetune
- Captioner
- LM으로 finetune.
- 웹 이미지 $I_w$가 주어지면 Captioner는 이미지당 하나의 합성 캡션 $T_s$를 생성.
- Filter
- 텍스트가 이미지와 일치를 학습 → ITC 및 ITM 으로 finetune.
- 원본 웹 텍스트 $T_w$ 와 합성 텍스트 $T_s$ 모두에서 노이즈가 있는 텍스트를 제거하며, ITM 헤드가 이미지와 일치하지 않는 것으로 예측하면 텍스트가 노이즈가 있는 것으로 간주.
- 마지막으로 필터링된 이미지-텍스트 쌍을 human-made 쌍과 결합하여 새로운 dataset를 형성 → 새로운 모델을 사전 학습하는 데 사용.
4. Experiments and Discussions
4.2. Effect of CapFilt

- C (captioner), F (filter) 포함시 retrieval, captioning 의 finetune, zeroshot 성능 증가

- 실제 캡션 $T_w$ 와 생성 캡션 $T_s$, 초록색이 filter가 accept.
4.4. Parameter Sharing and Decoupling

- 모델의 파라미터 수를 줄이기 위해 layer들의 파라미터를 공유하는 방법을 사용.
- Self-Attention layer를 제외한 layer들의 파라미터를 공유하니 성능 향상.
- → Self-Attention layer의 경우 encoder와 decoder의 작업 자체가 다르기 때문에 충돌이 일어날까봐 공유하지 않음.
5. Comparison with State-of-the-arts
5.1. Image-Text Retrieval
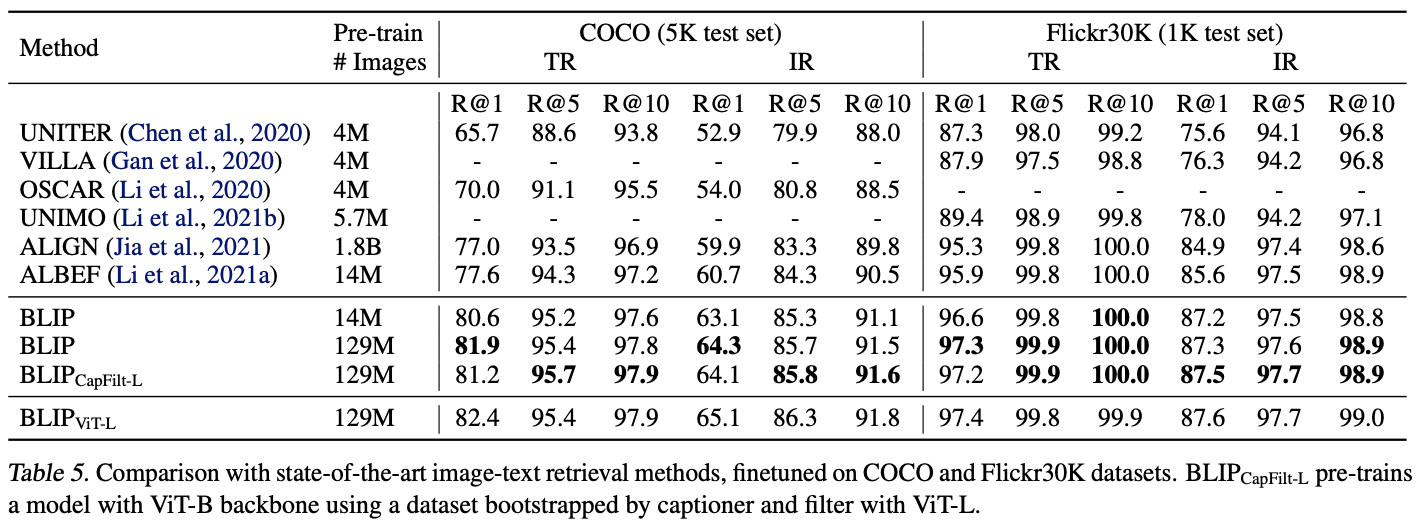
- Image-text retrieval 부분에서 SOTA 달성
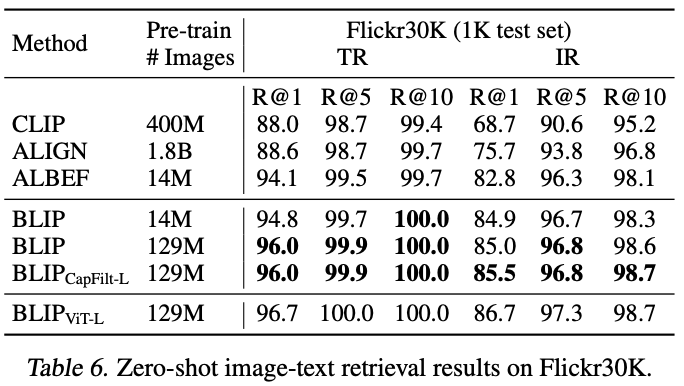
- Zero-shot 성능 차이 높음
5.2. Image Captioning

- Image captioing의 경우에도, 대부분 BLIP의 성능이 기존 모델들보다 우수.
- 큰 모델 LEMON 모델이 더 성능이 좋은 부분도 있지만, BLIP이 더 효율적.
5.3. Visual Question Answering (VQA)

5.6. Zero-shot Transfer to Video-Language Tasks


6. Additional Ablation Study
7. Conclusion
- BLIP의 성능을 더욱 향상시킬 수 있는 몇 가지 잠재적인 방향
- (1) Multiple rounds of dataset bootstrapping
- (2) 이미지당 여러 개의 합성 캡션을 생성하여 pre-training corpus 확대
- (3) 다양한 캡션과 필터를 학습하고 CapFilt에서 이들을 결합하여 앙상블을 모델링.
728x90
반응형
'AI > Multimodal' 카테고리의 다른 글
| Multimodal Prompting with Missing Modalities for Visual Recognition (2) | 2023.10.31 |
|---|

댓글