Simplify - Abstract
단일 제한되지 않은 이미지에서 인체의 3D 자세와 3D 모양을 자동으로 추정하는 첫 번째 방법 제안. 전체 3D 메쉬를 추정하여 2D 조인트만으로도 체형에 대한 정보를 얻을 수 있습니다.
사용 방법
- 3D 메쉬 추정은 인체의 복잡성, 관절, 폐색, 의류, 조명, 그리고 2D에서 3D를 추론하는 내재적 모호성 때문에 어렵지만
- 이를 해결하기 위해 먼저 최근 발표된 CNN 기반 방법인 DeepCut을 사용하여 2D 신체 관절 위치를 예측(bottom-up)합니다. 그런 다음 SMPL이라는 최근 발표된 통계 체형 모델을 2D 관절에 맞춥니다(top-down).
- 투사된 3D 모델 조인트와 검출된 2D 조인트 사이의 오차에 불이익을 주는 objective function을 최소화함으로써 그렇게 합니다.
- SMPL은 전체 모집단에 걸쳐 인간 형상의 상관관계를 포착하기 때문에, 아주 작은 데이터에 강력하게 맞출 수 있습니다. 또한 3D 모델을 활용하여 상호 개입을 일으키는 솔루션을 예방합니다.
- Lead Sports, HumanEva, Human 3.6m 데이터 세트에서 평가.
1 Introduction
단일 이미지에서 3D 인체 자세를 추정하는 것은 많은 애플리케이션에서 오랜 문제가 됩니다. 대부분의 이전 접근 방식은 포즈에만 초점을 맞추고 3D 인체 형태를 무시합니다. 여기서는 완전 자동적이고 2D 이미지에서 포즈와 모양을 모두 캡처하는 3D 메시를 추정하는 솔루션을 제공합니다. 우리는 두 단계로 문제를 해결합니다. 먼저 우리는 최근 제안된 1. DeepCut[36]이라는 컨볼루션 신경망(CNN)을 사용하여 2D 관절을 추정합니다. 지금까지 CNN은 2D 인간 포즈[20,34–36,51]를 추정하는 데는 성공했지만 한 이미지에서 3D 포즈 및 모양을 추정하는 데는 성공하지 못했습니다. 따라서 2. SMPL [30]이라는 3D 생성 모델을 사용하여 2D 조인트에서 3D 포즈 및 모양을 추정하는 두 번째 단계를 추가합니다. 우리가 "SMPLify"라고 부르는 전체적인 프레임워크는 bottom up 추정(CNN)에 이어 top-down 검증(생성 모델)의 고전적인 패러다임 내에 들어맞습니다. 그림 1에 몇 가지 예가 나와 있습니다.
2D 조인트에서 3D 자세를 추정하는 데 대한 긴 문헌이 있습니다. 이전의 방법과 달리, 우리의 접근 방식은 수천 개의 3D 스캔에서 훈련된 고품질 3D 인체 모델을 활용하므로 모집단의 형태 변화 통계뿐만 아니라 사람이 포즈로 변형되는 방법을 포착합니다. 여기서는 SMPL 바디 모델을 사용합니다 [30]. 중요한 통찰력은 그러한 모델이 인간의 체형에 대한 많은 정보를 포착하기 때문에 아주 적은 데이터에 적합할 수 있다는 것입니다.
우리는 objective function을 정의하고 포즈 및 모양을 직접 최적화하여 3D 모델의 투영된 관절이 CNN이 추정한 2D 관절에 근접하도록 합니다. 놀랍게도, 2D 관절만 적합하면 3D 체형의 타당한 추정치를 얻을 수 있습니다. 합성 데이터를 사용하여 정량적 평가를 수행한 후 2D 접합 위치에 놀라운 양의 3D 모양 정보가 포함되어 있음을 발견했습니다.
형상 통계량을 캡처하는 것 외에도, 생성 3D 모델을 사용하면 두 번째 이점이 있습니다. 즉, 상호 개입에 대해 추론할 수 있습니다. 이 지역의 이전 작업에서는 대부분 2D 조인트에서 추정된 3D 스틱 수치를 사용했습니다. 이러한 모델을 사용하면 신체 부위가 3D로 교차하기 때문에 불가능한 포즈를 쉽게 찾을 수 있습니다. 깊이 정보가 손실되면 솔루션이 모호해지기 때문에 이러한 솔루션은 2D에서 3D를 추론할 때 매우 흔합니다.
그러나 바디와 같은 복잡하고 볼록하지 않은 관절형 객체의 상호침투은 비용이 많이 듭니다. 이전 연구[14,15]와는 달리, 우리는 체형 및 자세와 관련하여 미분 가능한 상호침투 term를 제공합니다. 3D 체형이 주어지면 우리는 체형에 근사한 "캡슐" 세트를 정의합니다. 결정적으로 캡슐 차원은 모델 형상 모수에서 선형으로 회귀합니다. 이 표현을 사용하면 상호간 삽입을 효율적으로 계산할 수 있습니다. 이 용어가 잘못된 포즈를 방지하는 데 도움이 된다는 것을 보여줍니다.
SMPL은 성별에 따라 다릅니다. 즉, 여성과 남성의 형태 공간을 구분합니다. 우리의 방법을 완전히 자동으로 만들기 위해, 우리는 성별 중립적인 모델을 도입합니다. 성별을 모르면 이 모델을 이미지에 맞춥니다. 성별을 알면 더 나은 결과를 위해 성별에 맞는 모델을 사용합니다.
포즈 모호성을 다루기 위해서는, 좋은 포즈를 먼저 갖는 것이 중요합니다. 최근의 많은 방법은 CMU 데이터 세트[3]에서 희소하고 지나치게 완전한 사전을 배우거나 데이터 세트별 이전 버전을 학습합니다. 우리는 MoSh [29]를 사용하여 CMU mocap 마커 데이터[3]에 적합한 SMPL 모델에서 이전 오버포즈를 훈련합니다. 이 요인은 신체 부위의 상대적인 회전으로 표현되는 포즈와 함께 포즈로부터 형성됩니다. 그런 다음 우리는 이것으로부터 일반적인 다중 모델 포즈를 배웁니다.
이 방법을 입력과 정확히 동일한 2D 조인트를 사용하는 최근에 발표된 방법[4,39,58]과 비교합니다.
Contributions
- (1) 2D 관절에서 3D 몸매와 자세를 추정하는 첫 번째 완전 자동 방법
- (2) 모양과 자세와 관련하여 미분 가능한 interpenetration term
- (3) 3D 몸매 모델을 2D 관절에 일치시키는 새로운 목적 함수
- (4) 연구 목적으로 우리는 코드, 2D 관절 및 3D 모델 제공 (논문 [1]의 모든 예에 대한 모델).
2 Related Work
2D에서 3D 인체 자세를 회복하는 것은 근본적으로 모호하며 모든 방법은 이 모호함을 다른 방식으로 처리합니다. 여기에는 사용자 개입, 풍부한 이미지 기능 사용, 최적화 방법 개선, 가장 일반적으로 prior 지식 도입 등이 포함됩니다. 이러한 사전 지식은 일반적으로 뼈 길이에 인체측정학적인 제약을 가하는 "형상"과 그럴듯한 자세를 선호하고 불가능한 것을 배제하는 "포즈"를 모두 포함합니다. 멀티 카메라 이미지 또는 비디오 시퀀스에서 신체 자세와 모양을 추정하는 데 대한 많은 문헌이 있지만 [6,13,19,45] 여기서는 정적 이미지 방법에 중점을 둡니다. 우리는 또한 배경 감산을 위해 배경 이미지가 필요하지 않고 오히려 2D 관절에서 3D 포즈를 추론하는 방법에 초점을 맞춥니다. 대부분의 방법은 3D 관절이 알려져 있거나 추정된 2D 관절에 투영되도록 3D 골격을 찾는 것으로 문제를 공식화합니다.
이전 연구는 종종 특정 자세에서 이 골격skeleton을 "모양shape"으로 언급하기도 함. 이 연구에서 3D로 인체의 포즈-불변 표면을 의미하는 형태를 취하며, 사지의 관절 자세인 포즈와 이것을 구별합니다.
3D pose from 2D joints. 이러한 방법은 모두 2D 관절과 3D 골격 사이에 알려진 대응성을 가정합니다. 방법은 사지 길이 변동의 통계에 대해 서로 다른 가정을 합니다. Lee와 Chen[26]은 막대 그림의 알려진 사지 길이를 가정하고 Taylor[48]는 사지 길이(limb-length)의 비율을 알고 있다고 가정합니다. Parameswaran과 Chellappa[33]는 팔 길이가 사람마다 등각이며, 전지구적 스케일링에서만 다르다고 가정합니다. Barron과 Kakadiaris [7]은 인체측정학 표에서 추출한 극단값으로부터의 사지 길이 변화에 대한 통계 모델을 구축합니다. Jiang [21]은 CMU 데이터 세트[3]의 포즈를 예로 들면서 non-parametric 접근법을 취합니다.
최신 방법은 일반적으로 CMU 데이터 세트를 사용하고 그것으로부터 사지 길이와 포즈의 통계 모델을 학습합니다. 예를 들어, [11,39] 모두 포즈의 사전을 배우지만 사지 길이에 상당히 약한 인체측정학 모델을 사용합니다. Ahter와 Black [4]도 비슷한 접근 방식을 취하지만 포즈 의존적인 관절 각도 한계를 포착하는 새로운 포즈를 추가합니다. 저우 외. [58] 도형 사전을 배우지만, 이러한 포즈가 다른 카메라 뷰에서 나타나는 방식을 캡처하는 희소 기반을 만듭니다. 결과적으로 발생하는 최적화 문제를 더 쉽게 해결할 수 있다는 것을 보여줍니다. 폰스몰[37]은 다른 접근 방식: mocap에서 정성적인 "포즈비트"를 추정하여 이러한 "포즈비트"를 3D 포즈와 연관시킵니다. 위의 접근 방식은 약하거나 존재하지 않는 인체 모형들을 가지고 있습니다. 이와는 대조적으로, 이 논문은 수천 명의 사람들로부터 배운 더 강력한 체형 모델이 인구의 인체 측정학적인 제약을 포착한다고 주장합니다. 이러한 모델은 모호성을 줄여 문제를 더 쉽게 만듭니다. 또한, 우리는 3D 형태를 가지고 있기 때문에, 우리는 불가능한 포즈들을 피하면서 인터투입을 모델링할 수 있습니다.
3D pose and shape. 단일 영상에서 3D 체형을 추정하는 작업도 있습니다. 이 작업은 종종 좋은 실루엣을 사용할 수 있다고 가정합니다. 시그널[42] 실루엣이 제공된다고 가정하고, 실루엣에서 형상 형상을 계산한 다음 전문가 혼합을 사용하여 형상으로부터 3D 신체 자세와 형상을 예측합니다. 우리와 마찬가지로 그들은 문제를 상향식 차별적 방법과 하향식 생성 방법의 조합으로 봅니다. 이 경우 생성 모델(SCAPE [5])은 이미지 실루엣에 적합합니다. 이 방법이 완전 자동이라는 그들의 주장은 실루엣을 사용할 수 있는 경우에만 사실이지만, 그렇지 않은 경우가 많습니다. 이들은 완벽한 실루엣을 사용하여 제한된 결과 집합을 보여주며 포즈 정확도를 평가하지 않습니다. Guan et al. [14,15]는 수동으로 표시된 2D 관절을 사용하고 먼저 고전적인 방법을 사용하여 막대 형상의 3D 자세를 추정합니다 [26,48]. 이 스틱 그림의 포즈로 SCAPE 모델을 포즈하고, 모델을 영상에 투사하고, 이를 사용하여 GrabCut [40]으로 영상을 분할합니다. 그런 다음 SCAPE 모양을 맞추고 실루엣, 이미지 가장자리 및 음영 단서를 포함한 다양한 기능에 포즈를 취합니다. 카메라 초점 길이가 알려져 있거나 근사한 것으로 추정되고, 조명이 대략 초기화되며, 사람의 키가 알려져 있다고 가정합니다. 그들은 각각의 신체 부위를 볼록한 선체에 의해 모델링하는 삽입 용어를 사용합니다. 그런 다음 그들은 그 안에 얼마나 많은 다른 신체 점들이 있는지 보기 위해 각각의 말단을 확인하고 상호간 개입을 벌하는 벌칙 기능을 정의합니다. 이것은 쉬운 최적화를 인정하지 않습니다. 비슷하게, 하슬러[16]는 parametric body model을 실루엣에 맞춥니다. 일반적으로 알려진 분할과 수동으로 제공된 몇 가지 서신correspondences이 필요합니다. 배경이 간단한 경우 손과 발에 4개의 클릭된 지점을 사용하여 대략적인 핏을 확인한 다음 GrabCut을 사용하여 사람을 분할합니다. 그들은 이것을 하나의 이미지에서 보여줍니다. 저우[57]은 또한 parametric model of body shape을 fit하고 상당한 수동 개입을 사용하여 깔끔하게 분할된 실루엣에 포즈를 취합니다. 첸 [9]은 신체 형상의 파라메트릭 모델을 fit시키고 수동으로 추출한 실루엣에 포즈를 취하며 정량적 정확도를 평가하지 않습니다. 우리가 아는 바로는, 이전의 어떤 방법에서도 3D 체형을 추정하지 않고 2D 관절에서만 직접 자세를 취합니다. 우선, 불가능해 보일 수 있지만, 좋은 통계 모델을 고려할 때, 우리의 접근 방식은 놀라울 정도로 잘 작동합니다. SMPL[30]은 SPACE와 달리 명시적인 3D 조인트를 사용하여 사용할 수 있습니다. 이 조인트는 2D 조인트에 직접 투영됩니다. SMPL은 관절 위치가 신체의 3D 표면과 어떻게 관련되어 있는지 정의하여 관절의 모양을 추론할 수 있게 합니다. 물론 이것은 사람이 다양한 무게와 정확히 같은 사지 길이를 가질 수 있기 때문에 완벽하지는 않을 것입니다. 그러나 SMPL은 해부학적 관절을 나타내는 것이 아니라 표면 꼭지점의 함수로 나타냅니다. 이것은 모델 훈련 중에 관절과 모양을 결합시키고, 그들을 함께 해결하는 것이 중요하다는 것을 의미합니다.
Making it automatic. 위의 방법 중 어느 것도 자동적이지 않으며, 대부분 알려진 통신을 가정하고 일부는 상당한 수동 개입을 수반합니다. 그러나 단일 이미지에서 3D 포즈를 추론하는 전체 문제를 해결하는 몇 가지 방법이 있습니다. 시모세라[43,44]는 2D 부품 탐지가 신뢰할 수 없다는 점을 고려하여 3D 포즈와 2D 이미지 특징의 일치를 추정하는 확률적 모델을 공식화합니다. 왕[52] 사지 길이의 약한 모델을 사용하지만 [26] 이미지에서 자동으로 감지되는 조인트를 활용하고 L1 거리를 사용하여 이 조인트와 강력하게 일치시킵니다. 그들은 다른 방법에서와 같이 포즈를 나타내기 위해 희소 기준을 사용합니다. 저우[56] 2D 포즈 검출기[54]를 실행한 다음 3D 포즈를 최적화하여 특이치를 자동으로 거부합니다. Ahter와 Black [4]는 다른 2D 디텍터[23]를 실행하고 몇 개의 이미지에 해당 방법에 대한 결과를 표시합니다. 두 방법 모두 질적으로만 평가됩니다. Yasin[55] 검출된 2D 조인트를 사용하여 mocap 데이터 세트에서 가장 가까운 3D 포즈를 조회하는 비모수non-parametric 접근 방식을 사용합니다. Kostrikov와 Gall[24]은 회귀 숲과 3D 그림 모델을 결합하여 3D 관절을 회귀시킵니다. Ionescu[17]는 먼저 신체 부위 라벨을 예측하여 영상에서 3D 포즈를 예측하는 방법을 교육합니다. human3.6m에 대한 결과는 양호하지만 배경 분할을 사용할 수 없는 복잡한 영상에서는 테스트하지 않습니다. 쿨카르니 [25]는 단일 이미지에서 신체 자세를 추정하기 위해 확률적 프로그래밍 프레임워크와 함께 체형 및 포즈의 생성 모델을 사용합니다. 이들은 사람의 중심을 잘 잡고 잘린 시각적으로 간단한 영상을 다루며 3D 포즈 정확도를 평가하지 않습니다. 최근 딥 러닝의 발전으로 2D 관절 위치를 정확하게 추정하는 방법이 개발되고 있습니다 [36,53]. 우리는 최근 딥컷 방법[36]을 사용하고 있는데, 이 방법은 2D 탐지가 매우 우수합니다. 최근 연구[59]는 CNN을 사용하여 2D 관절 위치를 추정한 다음 단안 비디오 시퀀스를 사용하여 3D 포즈를 여기에 맞춥니다. 단일 이미지에 대한 결과는 표시되지 않습니다. 이러한 자동화된 방법 중 3D 체형을 추정하는 방법은 없습니다. 여기서는 2D 관절 탐지를 사용하여 단일 이미지에서 포즈 및 모양을 맞추는 전체 시스템을 시연합니다.
3 Method
그림 2는 시스템의 개요를 보여줍니다. 우리는 단일 입력 이미지를 촬영하고 딥컷 CNN [36]을 사용하여 2D 신체 관절인 Jest를 예측합니다. CNN은 각 2D 조인트에 대해 wi라는 신뢰 값을 제공합니다. 그런 다음 모델의 투영된 관절이 강력한 가중 오차 항을 최소화하도록 3D 신체 모형을 적합시킵니다. 본 연구에서는 스킨 정점 기반 모델인 SMPL [30]을 사용하여 2D 이미지를 촬영하고 포즈드 3D 메시인 SMPLify를 생성하는 시스템을 호출합니다.

- 단일 이미지가 주어지면 CNN 기반 방법을 사용하여 2D 관절 위치를 예측(핫 색상은 높은 신뢰도를 나타냄).
- 3D 신체 모형을 여기에 fit 3D 신체 형태와 자세를 추정합니다. 여기서는 HumanEva[41]에 대한 적합도를 보여 주며, 영상에 투영되어 다른 관점에서 표시됩니다. (온라인의 색상 그림)
body 모델은 shape β, pose θ, translation γ으로 매개 변수화된 함수 M(β, θ, γ)으로 정의됩니다. 함수의 출력은 정점이 6890개인 삼각형 표면 M입니다. 형상 모수 β는 수천 개의 등록된 스캔 훈련 세트에서 학습한 저차원 shape 공간의 계수입니다. 여기 우리는 세 가지 형태 모델 중 하나를 사용합니다: 남성, 여성, 그리고 성별 중립입니다. SMPL은 남성과 여성 모델만 정의합니다. 완전 자동 방법을 위해, 우리는 성별 SMPL 모델을 훈련하는 데 사용되는 약 2000명의 남성과 2000명의 여성 신체 형태를 사용하여 새로운 성별 중립 모델을 훈련했습니다. 성별이 알려지면 적절한 모델을 사용합니다. 사용된 모델은 gender-specific 분홍색을, 옅은 파란색 for gender-neutral, 성별에 따라 다르게 표시됩니다.
신체의 포즈는 23개의 관절이 있는 골격 rig에 의해 정의됩니다. 포즈 파라미터 represent는 부분들 사이의 상대적 회전의 축-각 표현을 나타냅니다. J(β)는 body shape에서 3D 골격 접합 위치를 예측하는 함수이다. SMPL에서 조인트는 표면 꼭지점의 희박한 선형 결합 또는 이와 동등하게 shape coefficients의 함수입니다. 관절은 global rigid transformation을 적용하여 임의 포즈로 설정할 수 있습니다. 다음에서, 우리는 포즈드 3D 관절 i을 Rθ(J(β)i)로 나타내며, 여기서 Rθ는 pose θ에 의해 유도되는 전역 강성 변형 global rigid transformation입니다. SMPL은 포즈 의존적 변형을 정의합니다. 성별 중립 형태 모델의 경우, 우리는 실제로 충분히 일반적인 여성 변형을 사용합니다. SMPL 모델과 DeepCut 골격은 관절이 약간 다릅니다. 딥컷 관절을 가장 유사한 SMPL 관절와 연결합니다. SMPL 관절을 영상에 투영하기 위해 파라미터 K로 정의된 투시 카메라 모델을 사용합니다.
3.1 Approximating Bodies with Capsules
우리는 이전의 방법들이 신체 부위들 사이의 interpenetration으로 인해 불가능한 3D 포즈를 만들어 낸다는 것을 발견했습니다. 3D 모양 모델의 장점은 탐지하고 방지할 수 있다는 것입니다. 그러나 컴퓨터 인터투입은 body와 같이 볼록하지 않은 복잡한 표면에는 비용이 많이 듭니다. 그래픽에서 프록시 지오메트리를 사용하여 충돌을 효율적으로 계산하는 것이 일반적입니다 [10, 우리는 이 접근 방식을 따르고 신체 표면을 "캡슐" 집합으로 근사합니다(그림 3). 각 캡슐에는 반지름과 축 길이가 있습니다.
From model shape parameters to 캡슐 파라미터(축 길이 및 반지름)에 이르는 regressor를 훈련시키고 키네마틱 체인에 의해 유도된 회전인 Rθ에 따라 캡슐을 포즈합니다. 구체적으로, 우리는 먼저 SMPL 학습에 사용되는 자세하지 않은 훈련용 몸매의 신체 표면에 손가락과 발가락을 제외한 신체 부위당 하나씩 20개의 캡슐을 fit합니다 [30]. 템플릿의 신체 관절에 수동으로 부착되는 캡슐부터 시작하여, 우리는 캡슐과 신체 표면 사이의 양방향 거리를 최소화하기 위해 그들의 반지름과 축 길이의 그라데이션 기반 최적화를 수행합니다. 그런 다음 교차 검증된 능선 회귀 분석cross-validated ridge regression을 사용하여 body shape 계수 β에서 캡슐의 반지름 및 축 길이까지의 선형 회귀를 학습합니다. 회귀 분석기가 훈련되면 절차가 한 번 더 반복되어 회귀 분석 출력으로 캡슐을 초기화합니다. 이전 연구는 근사를 사용하여 interpenetrations을 감지하지만 [38,46], 우리는 shape parameters의 이러한 회귀가 새로운 것이라고 믿습니다.
3.2 Objective Function
CNN이 감지한 2D 관절에 3D 포즈 및 모양을 맞추기 위해, 우리는 5개의 오차항, 즉 관절 기반 데이터 항, 3개의 포즈 priors, shape prior으로 이루어진 objective 함수를 최소화합니다. $E(β, θ) = $
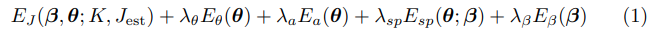
여기서 K는 카메라 파라미터이고 $λ_θ, λ_a, λ_{sp}, λ_β$는 스칼라 가중치입니다. 우리의 조인트 기반 데이터 용어는 추정된 조인트, Jest 및 해당 예상 SMPL 조인트 사이의 가중 2D 거리를 penalizes.
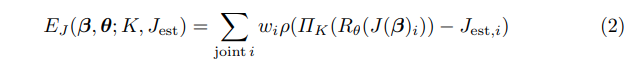
여기서 $Π_K$는 파라미터 K를 가진 카메라에 의해 유도된 3D에서 2D까지의 투영입니다. 우리는 각 관절의 기여도를 CNN이 제공한 추정치의 신뢰도에 따라 wi라 합니다. occlued 관절의 경우 일반적으로 이 값이 낮습니다. 이 경우 포즈는 포즈 pose priors로 구동됩니다. 잡음 추정을 처리하기 위해 강력한 차별화 가능한 Geman-McClure 페널티 함수ρ [12]를 사용합니다.
팔꿈치와 무릎에 penalizing 주기 위해 이상하게 구부러지는 pose prior를 도입합니다.

여기서 i 합계는 무릎과 팔꿈치 굽힘에 해당하는 포즈 파라미터(골격)입니다. 지수는 자연 제약 조건(예: 팔꿈치 및 무릎 과팽창)을 위반하는 회전에 강한 불이익을 줍니다. 조인트가 구부러지지 않은 경우 $θ_i$는 0입니다. 네거티브 벤딩은 자연스럽고 벌칙을 받지 않는 반면 포지티브 벤딩은 부자연스럽고 더 많은 벌칙을 받습니다.
3D 포즈 추정을 위한 대부분의 방법은 있을 수 없는 포즈보다 가능한 포즈를 선호하기 위해 어떤 포즈 prior를 사용합니다. 이전의 많은 방법과 마찬가지로 우리는 CMU 데이터 세트를 사용하기 전에 포즈를 훈련합니다 [3]. 포즈가 크게 달라진다는 점을 고려할 때 데이터의 다중 모달 특성을 나타내면서도 prior 계산은 쉽게 추적할 수 있도록 유지하는 것이 중요합니다. prior을 구축하기 위해, 우리는 MoSh [29]를 사용하여 SMPL을 CMU 마커 데이터에 적합시켜 얻은 포즈를 사용합니다. 그런 다음 100개의 피사체에 걸쳐 가우시안 혼합을 약 100만개의 포즈에 맞춥니다. 가우시안 혼합 모델을 최적화 프레임워크에서 직접 사용하는 것은 합계의 음의 로그를 최적화해야 하기 때문에 계산적으로 문제가 있습니다. [32]에 설명된 대로 max operator가 가우스 혼합물의 합계를 근사적으로 계산합니다.

여기서 gj는 N = 8인 MoG 모델의 weight이며, c는 솔버 구현에 필요한 양의 상수입니다. 최소 에너지의 모드가 변화하는 지점에서EθE_θ는 미분할 수 없지만, 현재 최적화 단계에서 최소 에너지를 사용하는 모드의 Jacobian에 의해EθE_θ의 Jacobian을 근사화합니다.
우리는 3.1절에 소개된 캡슐 근사를 이용하는 interpenetration error term를 정의합니다. 우리는 오류 용어를 “incompatible” capsules 사이의 교차 볼륨(즉, 자연스러운 포즈에서 교차하지 않는 캡슐)과 연관시킵니다. 캡슐 교차점의 부피는 계산이 간단하지 않기 때문에 캡슐 축을 따라 중심 C(θ, β)가 있고 캡슐 반경에 해당하는 반지름 r(β)가 있는 구(球)로 캡슐을 단순화합니다. 우리의 페널티 용어는 [47]의 3D 가우스 모델을 혼합한 것에서 영감을 받았습니다. 우리는 각 구에 대해 σ(β) = r(β)/3을 갖는 3D 등방성 가우시안(β)을 고려하고, 패널티를 "불가능한" 부분에 해당하는 가우시안 곱의 적분의 스케일 버전으로 정의합니다.

summation이 모든 구에 걸쳐 있는 경우 i 및 I(i)는 i와 호환되지 않는 구입니다. 이 용어는 불이익을 주지만 엄격히 interpenetrations를 피하지는 않는다는 점에 유의하십시오. 그러나 원하는 대로 이 용어는 자세와 모양에 따라 미분될 수 있습니다. 또한 우리는 이 용어를 모양 최적화에 사용하지 않습니다. 왜냐하면 이것은 body shape이 간 삽입을 피하기 위해 얇아지는 쪽으로 bias 되기 때문입니다.
다음과 같이 정의된 $E_β(β)$ shape prior을 사용합니다.

여기서Σβ−1Σ^{-1}_β은 대각 행렬로, SMPL 훈련 세트의 도형에서 주성분 분석Principal Component Analysis을 통해 추정된 특이값 제곱squared singular values을 가진 대각 행렬입니다. shape coefficients β는 구문에 의한 평균이 0이라는 점에 유의하십시오.
3.3 Optimization
카메라 변환 및 차체 방향을 알 수 없다고 가정하지만 카메라 초점 길이 또는 대략적인 추정치가 알려져 있어야 합니다. 우리는 사람이 이미지 평면에 평행하게 서 있다고 가정하여 카메라 변환(등가)을 초기화합니다. 구체적으로, 우리는 평균 SMPL 형상의 몸통 길이와 예측된 2D 관절에 의해 정의된 유사한 삼각형의 비율을 통해 깊이를 추정합니다. 이 가정이 항상 진실인 것은 아니므로, 우리는 카메라 변환 및 신체 방향과 관련하여 몸통 관절에 대한 EJ를 최소화함으로써 이 추정치를 더욱 세분화합니다. 우리는 이 최적화 동안 평균 모양에 β를 고정시킵니다. 번역과 함께 최적화하기에는 문제가 너무 제한되지 않기 때문에, 우리는 초점 길이를 최적화하지 않습니다.
카메라 translation을 추정한 후, 우리는 단계적 접근법으로 Eq.(1)를 최소화하여 모델에 맞춥니다. λθ and λβ의 높은 값으로 시작하여 이후 최적화 단계에서 점차 감소시키는 것이 국소 최소화를 피하는 데 효과적이라는 것을 관찰했습니다.
피사체가 측면 뷰에 포착되면 신체 어느 방향을 향하는지 평가하는 것이 모호할 수 있습니다. 이를 해결하기 위해 CNN 추정 2D 어깨 관절 사이의 2D 거리가 임계값 미만일 때 두 가지 초기화를 시도했습니다. 처음에는 위와 같이 신체 방향을 추정한 다음 그 방향을 180도 회전한 것입니다. 마지막으로 EJ가 가장 낮은 핏을 선택합니다.
Powell의 Dogleg 메서드[31]를 사용하여 Eq.(1)를 최소화하고 OpenDR 및 Chulful[2,28]을 사용합니다. 단일 이미지를 최적화하는 데 일반 데스크톱 시스템에서 1분도 걸리지 않습니다.
4 Evaluation
우리는 3D 포즈 및 3D 형상 추정의 정확성을 평가합니다. 3D 포즈의 정량적quantitative 평가를 위해 공개 데이터 세트 두 개 - 휴먼 에바 I [41]과 휴먼 3.6M[18] 사용. 세 가지 최첨단 방법[4,39,58]에 대한 접근 방식을 비교하고 절제ablation 분석에도 이러한 데이터를 사용합니다. 두 개의 실제 데이터 세트 모두 실험실 환경이 제한되고 포즈가 제한적입니다. 결과적으로, 우리는 리즈 스포츠 데이터 세트(LSP)의 더 까다로운 데이터에 대한 질적qualitative 분석을 수행합니다 [22]. 실제 3D 형상을 가진 영상이 거의 없기 때문에 형상을 정량적으로 평가하는 것이 더 어렵습니다. 따라서 합성 데이터를 사용하여 정량적 평가를 수행하여 노이즈로 손상된 2D 접합에서 모양을 얼마나 잘 복구할 수 있는지 평가합니다. 모든 실험에는 10개의 체형 계수가 사용됩니다. 우리는 HumanEva 훈련 데이터에서 Eq.(1)의 λi 가중치를 조정하고 이러한 값을 모든 실험에 사용합니다.
4.1 Quantitative Evaluation: Synthetic Data
SMPL 모양과 포즈 공간에서 synthetic bodies를 채취하고 알려진 카메라로 이미지에 접합을 투영합니다. 우리는 640 × 480 해상도의 남성형 1000개, 여성형 1000개의 이미지를 생성합니다.
첫 번째 실험에서는 다양한 양의 i.i.d 가우스 노이즈(표준 편차(std) 1~5픽셀)를 각 2D 조인트에 추가합니다 . 우리는 Eq.(1)를 최소화하고 Eq. (2)에서 1의 관절에 대한 신뢰 가중치를 설정하여 자세와 모양을 해결합니다. 그림 4(왼쪽)는 표준canonical 포즈에서 추정된 형상과 true shape 사이의 평균 vertex-to-vertex 유클리드 오류를 보여줍니다. 성별에 맞는 모델을 fit 했는데, 형상 추정 결과는 단순히 평균 형상(그림의 빨간색 선)을 추정하는 것보다 더 정확합니다. 이는 관절이 소음에 비교적 강한 체형에 대한 정보를 전달한다는 것을 보여줍니다.
두 번째 실험에서는 포즈가 알려져 있다고 가정하고, 체형을 정확하게 추정하기 위해 얼마나 많은 관절이 필요한지 이해하려고 노력합니다. 우리는 23개의 SMPL 관절의 전체 세트, 몸통과 팔다리에 해당하는 12개의 관절의 부분 집합(머리, 척추, 손 및 발 제외), 그리고 몸통의 4개의 관절과 관련하여 Eq.(2)를 최소화하여 SMPL을 지상 실측 2D 관절에 맞춥니다. 위와 같이, 우리는 표준 포즈에서 추정된 모양과 실제 모양 사이의 평균 유클리드 오류를 측정합니다. 결과는 그림 4(오른쪽)에 나와 있습니다. 관절이 많을수록 몸매도 좋아지는 것으로 추정됩니다. 우리가 아는 바로는, 이것은 단지 2D 관절에서 3D 체형을 추정하는 첫 번째 시연입니다. 물론 일부 조인트는 신뢰성 있게 추정하기 어려울 수 있습니다. 아래의 실제 데이터에 대해 평가합니다.
4.2 Quantitative Evaluation: Real Data
HumanEva-I. 우리는 HumanEva 데이터 세트의 단일 프레임에 대한 포즈 추정 정확도를 평가합니다 [41]. 표준 절차에 따라 "검증" 집합에서 피험자 1, 2, 3의 걷기 및 상자 시퀀스를 평가합니다 [849]. 성별이 알려져 있다고 가정하고 성별별 SMPL 모델을 적용합니다.
많은 방법들이 HumanEva에 대한 sequence-specific pose priors을 훈련합니다. 우리는 그렇게 하지 않습니다. 그러나 우리는 HumanEva 훈련 세트에 대한 weights를 조정하고 SMPL 조인트에서 HumanEva의 3D 골격 표현에 대한 매핑을 학습합니다. 이를 위해 SMPL 모델을 MoSh를 사용하여 훈련 세트의 원시 모캡 마커 데이터에 적합시켜 체형 및 자세를 추정합니다. 그런 다음 우리는 신체 꼭지점(equivalently shape parameters β)에서 HumanEva 3D 관절로 선형 회귀기를 훈련합니다. 이 작업은 모든 과목의 교육 데이터에 대해 한 번 수행되고 고정됩니다. 우리는 회귀된 3D 조인트를 평가를 위해 출력물로 사용합니다.
우리는 우리의 방법을 우리와 같이 2D 관절에서 3D 자세를 예측하는 세 가지 최첨단 방법[4,39,58]과 비교했습니다. 우리는 지상 실측과 예측된 3D 접합 위치 사이의 평균 유클리드 거리를 보고합니다. 오류를 계산하기 전에 유사성 변환을 적용하여 모든 프레임에 대한 Procrusts 분석을 통해 재구성된 3D 관절을 공통 프레임에 정렬합니다. 모든 방법에 대한 입력은 동일합니다. 2D 조인트는 DeepCut [36]에서 감지됩니다. DeepCut은 정량적 평가에 사용되는 데이터 세트에 대해 훈련되지 않았다는 점을 기억하십시오. 이러한 접근 방식은 3D 관절의 골격 구조가 다르다는 점에 유의하십시오. 우리는 모든 표현에 걸쳐 의미적으로 대응하는 14개의 관절의 하위 집합에 대해 평가합니다. 이 데이터 세트의 경우 실측 초점 길이를 사용합니다.
표 1은 SMPLify가 모든 시퀀스에서 가장 낮은 오류를 달성한 정량적 결과를 보여줍니다. Zhou 등의 최근 방법 [58]은 매우 훌륭하지만, 우리는 우리의 접근 방식이 개념적으로 더 단순하고 더 정확하다고 주장합니다. 우리는 단순히 신체 모형을 2D 데이터에 맞추고 모델이 솔루션을 제한하도록 합니다. 이렇게 하면 2D 조인트를 3D로 "리프트"할 수 있을 뿐만 아니라 SMPLify는 다양한 용도에 즉시 사용할 수 있는 껍질이 벗겨진 vertex 기반 모델도 만들어냅니다.
방법에 대한 통찰력을 얻기 위해 다양한 pose priors과 interpenetration페널티 항을 평가하는 절제 연구(표 2)를 수행합니다. 먼저, 우리는 동일한 데이터에서 훈련된 단일 가우시안을 사용하는 Eθ로 이전 mixture-mode 기반 포즈를 교체합니다. 이로 인해 성능이 크게 저하됩니다. 다음에는 인터네셔널 용어를 추가하지만, 3D 조인트 오류에는 큰 영향을 미치지 않습니다. 그러나, 질적으로, 우리는 그것이 그림 5에 설명된 것처럼 다양한 포즈와 시야각을 가진 더 복잡한 데이터 세트에서 차이를 만든다는 것을 발견합니다.
Human3.6M. 우리는 포즈의 범위가 더 넓은 인간 3.6M 데이터 세트[18]에 대해 동일한 분석을 수행합니다. [27,49,59]에 이어 S9 및 S11 과목의 시퀀스에 대한 결과를 보고합니다. 우리는 시험 1에서 전면 카메라("cam3")에서 캡처한 다섯 가지 다른 동작 시퀀스에 대해 평가합니다. 이러한 시퀀스는 평균 2000프레임으로 구성되며 모든 프레임에 대해 개별적으로 평가합니다. 위와 같이, 우리는 SMPL 체형에서 데이터 세트에 사용되는 3D 관절 표현에 이르는 회귀기를 훈련시키기 위해 훈련 Mocap과 MoSh를 사용합니다. 이 외에는 어떠한 방식으로도 교육 세트를 사용하지 않습니다. 피사체가 이미지의 경계에 더 가깝기 때문에 초점 길이와 왜곡 계수가 알려져 있다고 가정합니다. 인간 3.6M에 대한 평가는 표 3에 나타나 있습니다. 여기서 우리의 방법은 다시 가장 낮은 평균 3D 오류를 달성합니다. 직접 비교할 수는 없지만 Ionescue [17]은 이 데이터 세트에 92mm의 오류를 보고합니다.
4.3 Qualitative Evaluation
여기서는 리즈 스포츠 포즈(LSP) 데이터 세트의 이미지에 SMPLify를 적용합니다 [22]. 이것들은 포즈, 이미지 해상도, 옷, 조명, 배경 면에서 HumanEva or Human3.6M보다 훨씬 더 복잡합니다. 하지만 CNN은 여전히 2D 포즈를 잘 추정합니다. 우리는 LSP 테스트 세트에서만 결과를 보여줍니다. 그림 6은 시스템이 잘 작동하는 몇 가지 대표적인 예를 보여줍니다. 이 그림은 성별 중립 및 성별별 SMPL 모델 모두에 대한 결과를 보여 줍니다. 이 선택은 포즈에는 시각적 효과가 거의 없습니다. 성별에 따라 이미지에 레이블을 수동으로 지정합니다.
그림 8은 각 데이터 세트의 몇 가지 영상에 대한 여러 방법의 결과를 시각적으로 비교합니다. 다른 방법들은 사지 길이가 어떻게 상관관계가 있는지에 대한 강력한 모델이 없는 것으로 인해 어려움을 겪고 있습니다. LSP에는 복잡한 포즈가 포함되어 있으며, 이러한 포즈는 종종 interpenetration term의 가치를 보여줍니다. 그림 5는 두 가지 예를 보여줍니다. 그림 7은 LSP의 몇 가지 고장 사례를 보여줍니다. 이 중 일부는 사지가 잘못 감지되거나 다른 사람들의 사지와 일치하는 CNN 실패에서 비롯됩니다. 다른 실패는 challenging depth ambiguities 때문입니다. 자세한 결과는 보조 자료 [1]을 참조하십시오.
5 Conclusions
Acknowledgements.
'AI > 포즈 추정' 카테고리의 다른 글
| Deep Dual Consecutive Network for Human Pose Estimation (2) | 2021.08.27 |
|---|---|
| A Graph Attention Spatio-temporal Convolutional Network for 3D Human Pose Estimation in Video (0) | 2021.07.30 |
| Monocular, One-stage, Regression of Multiple 3D People (0) | 2021.07.29 |
| Deep High-Resolution Representation Learning for Human Pose Estimation (0) | 2021.07.25 |
| LSTM_Pose_Machines (0) | 2021.07.13 |




댓글