Abstract
복잡한 상황에서의 멀티 프레임 휴먼 포즈 예측은 어렵다. 정적 이미지에 대해 놀라운 결과를 보여주었지만 비디오 시퀀스에 이러한 모델을 적용하면 성능이 저하된다.
비디오의 문제점 - 비디오 프레임 간의 시간 의존성을 캡처하지 못해 발생하는 모션 블러, 비디오 아웃포커스 또는 occlusion.
기존의 반복 신경망을 직접 사용하는 것은 공간적 맥락, 특히 occlusion를 다루는 데 있어 경험적 어려움을 야기한다.
이 논문에서는 키포인트 감지를 용이하게 하기 위해 비디오 프레임 사이의 풍부한 시간적 신호를 활용하여 새로운 멀티 프레임 휴먼 포즈 추정 프레임워크를 제안한다. 여기엔 세 가지 모듈식 구성요소가 설계되어 있습니다. Pose Residual Fusion 모듈이 weighted 포즈 residual를 양방향으로 계산하는 동안 Pose Temporal Merge는 키포인트 시공간 컨텍스트를 인코딩하여 효과적인 검색 범위를 생성합니다. 그런 다음 포즈 추정의 효율적인 조정을 위해 당사의 포즈 보정 네트워크를 통해 처리한다.
1. Introduction
인체 자세 평가는 해부학적 핵심 요소(예: 손목, 발목 등) 또는 신체 부위를 찾는 것을 목표로 하는 컴퓨터 시력의 근본적인 문제이다. 이전의 방법은 확률론적 그래픽 모델 또는 그림 구조 모델을 채택했다. 최근의 방법들은 심층 신경 네트워크 (CNN)의 성공에 기초하고 있습니다. 이 작업에서 뛰어난 성과를 달성한다. 안타깝게도, 최근의 최신 방법 대부분은 비디오 입력을 처리할 때 성능이 크게 저하되는 정적 이미지에 맞게 설계되었다.

이 문제를 해결하기 위한 직접적이고 직관적인 접근법은
- 비디오 프레임 간의 시간적 의존성뿐만 아니라 기하학적 일관성을 모델링하기 위해 LSTM(장기 단기 메모리), GRU(게이트 반복 장치) 또는 3DCNN과 같은 반복 신경 네트워크(RNN)를 사용하는 것이다.
- 또 다른 해결 방법으로는 인접 프레임의 높은 신뢰도의 키포인트로 기본 예측을 fine tune하는 것이다. 두 프레임마다 조밀한 옵티컬 플로우를 계산하고, 추가 흐름 기반 표현을 활용하여 예측을 조정할 것을 제안한다.
그러나 이 접근법은 옵티컬 플로우를 정확하게 계산할 수 있을 때 유의미하고 모션 흐림 또는 초점 제거와 관련된 경우 이미지 품질이 좋지 않으면 옵티컬 플로우가 부정확해져 성능이 저하된다.
이 논문에서는 기존 방식의 단점을 보완하기 위해 이중 시간 방향의 연속 프레임을 통합하여 영상의 포즈 평가를 개선할 것을 제안한다. 자세 추정을 위한 이중 연속 네트워크(DCPose)라는 프레임워크는 먼저 공간-시간적 키를 인코딩한다. 컨텍스트를 지역화된 검색 범위로 지정하고 residual를 계산한 다음 키포인트 히트맵 추정치를 fine tune한다. 구체적으로 DCPose 파이프라인 내에서 세 가지 작업별 모듈을 설계한다.
- 그림 1과 같이 PTM(Pose Temporal Merge) 네트워크는 그룹 컨볼루션을 통해 연속된 비디오 세그먼트(예: 3개의 프레임)를 통해 키포인트의 검색 범위를 localize.
- 현재 프레임과 인접 프레임 사이의 포즈 residual를 효율적으로 얻기 위해 포즈 잔류 융접(PRF) 네트워크가 도입됩니다. PRF는 시간 거리를 명시적으로 활용하여 프레임 간 키 포인트 오프셋을 계산.
- 마지막으로, 지역화된 검색 범위에서 키포인트 히트맵을 다시 샘플링하기 위해 확장 속도가 다른 5개의 병렬 컨볼루션 레이어로 구성된 Pose Correction Network(PCN)를 제안.
DCPose 아키텍처는 PoseWarper 아키텍처를 세 가지 방법으로 확장.
- PoseWarper는 프레임 간에 효과적인 레이블 전파를 가능하게 하는 데 중점을 두고 있으며, 우리는 라벨이 부착되지 않은 인접 프레임의 모션 컨텍스트 및 시간 정보를 사용하여 현재 프레임의 포즈 예측을 구체화하는 것을 목표로 합니다.
- 두 방향의 정보가 활용되고 프레임 간의 weighted residual를 명시적으로 고려합니다.
- 학습된 뒤틀림 연산을 하나의 인접 프레임에서 히트맵에 적용하는 대신, 새 네트워크는 인접 프레임과 현재 프레임의 히트맵을 함께 결합합니다.
주요 기여
- 프레임 전체에 걸쳐 키포인트를 효과적으로 집계하고 검색 범위를 식별하기 위한 새로운 Pose Temporal Merge 네트워크,
- 프레임 전체에 걸쳐 weighted 포즈 residual를 효율적으로 계산하기 위한 Pose Residual Fusion 네트워크,
- 포즈 보정 네트워크(Pose Correction Network) 자세 추정치를 정교한 검색 범위로 업데이트하고 pose residual information를 제공합니다.
- PoseTrack2017 및 PoseTrack2018 Multi-frame Person Pose Estimation Challenge에서 최첨단 결과를 달성합니다.
2. Related Work
2.1. Imaged Based Multi Person Pose Estimation
이전의 이미지 기반 인체 포즈 추정은 일반적으로 인체가 트리 구조 또는 forest 구조로 표현되는 그림 구조 모델 패러다임에 해당한다. 효율적인 추론이 가능함에도 불구하고, 이러한 접근 방식은 신체 부위 간의 복잡한 관계를 모델링하는 데 불충분한 경향이 있으며, 이러한 약점은 시간적 정보가 그림에 들어갈 때 더욱 부각된다. 최근에는 다양한 분야에서 우수한 성과로 신경망을 기반으로 한 방법이 주목을 받고 있다. 어떤 방법은 이미지 피쳐를 회귀시켜 골격 조인트를 직접 출력한다. 또 다른 접근 방식은 확률 히트맵을 사용하여 관절 위치를 나타냅니다. 최적화에 대한 어려움 감소로 인해, 그 이후로 히트맵 기반 포즈 추정이 널리 채택되었습니다. 일반적으로 이러한 방법은 부품 기반 프레임워크(상향식)와 2단계 프레임워크(하향식)로 분류할 수 있다. 상향식 접근 방식은 먼저 개별 신체 부위를 감지한 다음 이러한 구성 부품을 전체 사람에게 조립한다. 최근 연구는 고해상도 기능 맵을 유지하기 위해 멀티 스케일 퓨전을 수행하는 HRNet을 제안합니다.
2.2. Video Based Multi Person Pose Estimation
기존 이미지 레벨 방법을 비디오 시퀀스에 직접 적용하는 것은 주로 비디오 프레임 간의 시간 의존성을 캡처하지 못했기 때문에 만족스럽지 못한 예측을 생성합니다. 결과적으로 이러한 모델은 모션 흐림, 비디오 초점 제거 또는 비디오 입력에서 자주 발생하는 폐색을 처리하지 못한다. 모든 연속 프레임 사이의 조밀한 optical flow을 계산하거나 컨볼루션 포즈 기계를 공간적 맥락 외에 시간적 정보를 모델링하기 위한 컨볼루션 LSTM으로 대체한다. 이러한 접근 방식의 주요 단점은 폐색에 의해 심각한 영향을 받고 있습니다.
3. Approach
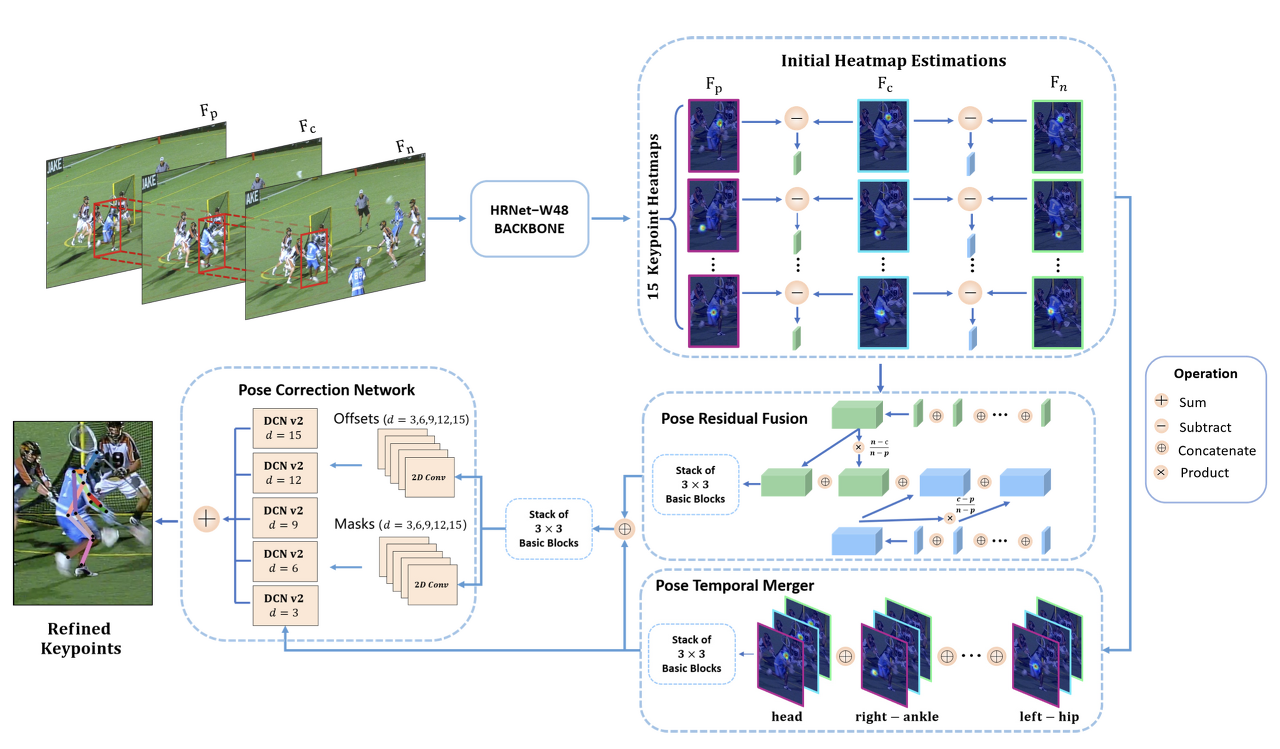
DCPose의 파이프라인. 현재 프레임 $F_c$의 키포인트 감지를 개선하기 위해 이전 프레임 $F_p$와 향후 프레임 $F_n$의 추가 시간 정보를 사용한다. 프레임 창 $[c - T, c + T]$ 내에서 $F_p$ 및 $F_n$이 선택되는데 $p ∈ [c − T,c)$ 와 $n ∈ (c,c + T]$는 각각 프레임 인덱스이다. $F_c$에서 개별 인간을 위한 바운딩 박스는 YOLO v3에 의해 획득된다. 각 바운딩 박스는 25% 확대되며 $F_p$ 및 $F_n$에서 동일한 인물을 자르는 데 추가로 사용됩니다. 따라서 비디오의 인간 i $Clip_i(p, c, n)$는 비디오 세그먼트로 구성되고, 예비 키포인트 히트맵 추정치 (p, c, n)를 출력하는 역할을 하는 백본 네트워크에 공급된다. 포즈 히트맵 (p, c, n)는 두 개의 모듈식 네트워크, 즉 PTM(Pose Temporal Merge)과 PRF(Pose Residual Fusion)를 통해 병렬로 처리되는데 PTM은 공간 집계를 인코딩하는 $\phi_i(p, c, n)$와 PRF는 두 방향으로 residual를 나타내는 $\Psi_i(p, c, n)$를 계산한다. 그러면 두 텐서 $\phi_i(p, c, n)$와 $\Psi_i(p, c, n)$가 동시에 PCN(Pose Correction Network)에 공급되어 초기 포즈를 개선한다.
3.1. Pose Temporal Merger
PTM(Pose Temporal Merge)의 동기
- 기존 포즈 추정 방법이 동영상의 성능 저하를 겪고 있지만, 이러한 예측은 여전히 핵심 공간 위치 근사치에 유용한 정보를 제공한다는 것.
- 시간적 일관성. 즉, 사람의 자세는 매우 적은 프레임 간격(일반적으로 프레임당 1/60에서 1/25초)에 걸쳐 극적이고 갑작스러운 변화를 겪지 않습니다. 따라서 PTM을 설계하여 초기 예측(백본 네트워크)을 기반으로 키포인트 공간 컨텍스트를 인코딩하여 제한된 범위 내에서 자세 예측의 미세화 및 교정을 용이하게 하는 압축된 검색 범위를 제공합니다.
$H_i$ 의 경우, 백본 네트워크는 초기 키 포인트 히트맵 반환합니다. 기본적으로, $H_i (p, c, n) = h_i (p) + h_i (c) + h_i (n)$의 직접 더해 병합한다. 하지만 Fp와 Fn에서 추출될 수 있는 추가 정보는 에서 시간적 거리에 반비례할 것이라는 직관을 다음과 같이 공식화한다.

($p, c, n$ 프레임 인덱스) 현재 프레임에 일시적으로 더 가까운 프레임에 더 높은 가중치를 명시적으로 할당합니다.
컨볼루션 연산이 가중치를 조정(특징)하는 역할을 하기 때문에 컨볼루션을 식1 에 사용. 그러나 단일 조인트의 병합 키포인트 히트맵을 위한 계산에 모든 조인트 채널을 포함하면 중복성이 발생한다. 예를 들어, 왼쪽 손목의 공간 컨텍스트를 인코딩할 때 머리와 발목과 같은 다른 관절과 관련된 경우 방향 감각이 없을 수 있으며 혼동을 일으킬 수도 있다. 따라서 각 접합에 대해 병합된 키포인트 히트맵을 계산하기 위한 특정 시간 정보만 포함하도록 그룹 컨볼루션을 통해 구현했다. 관절에 따라 키포인트 히트맵 $h_i(p), h_i(c), h_i(n)$ 을 다시 그룹화하고, 이를 다음과 같이 나타낼 수 있는 피쳐 텐서 $\phi_i$에 쌓는다.
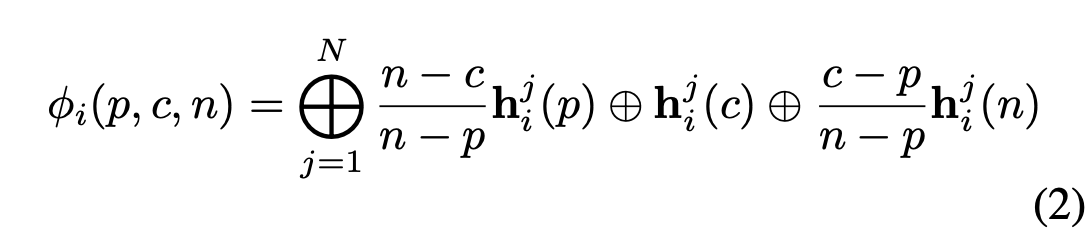
여기서는 concat을 이용했고, j는 총 N개의 조인트에 대한 j번째 조인트이다. 이후 피쳐 텐서 $\phi_i$ 가 3 x 3개의 residual 블록 스택에 입력되어 병합된 키포인트 히트맵 $\phi_i(p, c, n)$를 생성.

이 그룹 컨볼루션은 관련 없는 조인트의 장애를 제거할 뿐만 아니라 중복성을 제거하고 필요한 모델 파라미터의 양을 줄여준다. 그룹 CNN 운영은 픽셀 레벨에서 서로 다른 가중치를 허용하고 엔드 투 엔드 모델을 학습하는 데 도움이 되기 때문에 1차 평가에서 키포인트 히트맵을 직접 합산하는 데에도 유리하다. (그림 1에 PTM의 키포인트 히트맵의 시각적 결과)
3.2. Pose Residual Fusion
PTM의 키포인트 히트맵의 공간 집적과 병행하여, PRF는 추가적인 유리한 시간적 단서 역할을 할 포즈 residual를 계산하는 것을 목표로 한다. 키포인트 히트맵이 $h_i (p), h_i (c), h_i (n)$이면 포즈 residual 피쳐를 다음과 같이 계산한다.

$\Psi_i$ 는 원래 자세 residual $\psi_i (p, c), \psi_i (c,n)$ 및 weighted 버전을 연결하고, 여기서 시간 거리에 따라 가중치를 구한다. PTM과 마찬가지로,$\psi_i$ 는 3 x 3개의 residual 블록 스택을 통해 처리되어 최종 자세 residual 특성 $\psi_i (p, c, n)$ 를 만든다.

3.3. Pose Correction Network
병합된 키포인트 히트맵 $\phi_i(p, c, n)$ 및 포즈 residual 특성 텐서 $\Psi_i(p, c, n)$가 주어졌을 때, 우리의 포즈 보정 네트워크는 초기 키포인트 히트맵 추정 hi(c)를 미세 조정하여 최종 키포인트 히트맵을 산출한다. 일차적으로, 포즈 잔류 특성 텐서 $\Psi_i (p, c, n)$ 는 서로 다른 확장 속도 $d \in \{3, 6, 9, 12, 15\}$ 의 5개의 병렬 3 × 3 컨볼루션 레이어에 대한 입력으로 사용된다. 이 계산은 후속 변형 가능한 컨볼루션 레이어의 5개 커널에 대해 5개의 오프셋 그룹을 제공한다. 공식적으로, 오프셋은 다음과 같이 계산돤다.
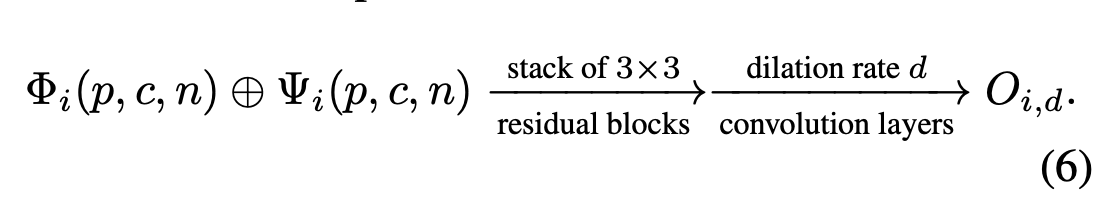
서로 다른 확장 속도는 유효 수용 필드의 크기를 변화시키는 데 해당하며, 확장 속도를 확대하면 수용 수용 필드의 범위가 증가한다. 확장 속도가 작을수록 로컬 모양에 중점을 두므로 미세한 모션 컨텍스트를 캡처하는 데 더 민감하다. 반대로 확장률이 높으면 글로벌 표현을 인코딩하고 더 큰 공간 범위의 관련 정보를 캡처할 수 있다. 오프셋 계산 외에도 병합된 키포인트 히트맵을 유사한 컨볼루션 레이어에 공급하고 다음과 같은 마스크 Md 다섯 세트를 얻는다.
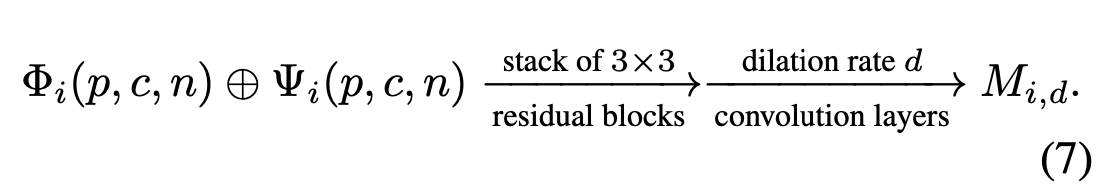
오프셋 O 및 마스크 M 계산을 위한 두 확장 컨볼루션 구조의 파라미터는 독립적이고 마스크 $M_d$는 Convolution 커널의 가중치 매트릭스로 간주할 수 있다.
다양한 dilation d에서 Deformable 컨볼루션 V2 (DCN v2)를 통해 PCN을 구현합니다. DCN v2는
- 병합된 키포인트 히트맵 $\Phi_i (p, c, n),$
- 커널 오프셋 $O_{i,d},$
- dilated rate d에 대한 사람 i 히트맵를 위한 마스크 $M_{i,d}$을 생산.
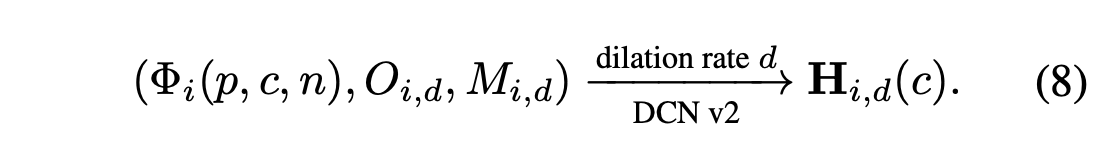
5개의 확장 속도에 대한 5개의 출력을 요약하고 정규화하여 개인 i에 대한 최종 포즈 예측을 산출.

궁극적으로 위의 절차는 각 인간 i에 대해 수행됩니다. DCPose 프레임워크에서 Fp 및 Fn의 추가 신호를 효과적으로 활용하여 최종 포즈 히트맵을 개선한다.

3.4. Implementation Details
Backbone Model
단일 이미지 포즈 추정을 위한 탁월한 성능을 보이는 HRNet-W48 를 사용.
Training
PyTorch로 구현. 교육 중에 우리는 ground truth 사람 바운딩 박스를 사용하여 입력 시퀀스로 person i에 대한$Clip_i(p, c, n)$를 생성후 맨 처음과 끝에는 동일한 패딩을 적용합니다. 즉, Fc에서 앞뒤로 확장할 프레임이 없으면 Fp 또는 Fn이 Fc로 대체됩니다. PoseTrack 데이터셋에서 사전 교육된 HRNet-W48을 백본으로 활용하고, 교육 내내 백본 파라미터를 동결하여 DCPose의 후속 구성요소를 통해서만 역전파한다.
Loss function
cost 함수로 표준 포즈 추정 손실 함수를 채용하고 있다. 교육은 모든 조인트에 대한 예측 및 ground truth 사이의 총 유클리드 또는 L2 거리를 최소화하는 것을 목표로 하고 비용 함수는 다음과 같이 정의된다.

여기서 G(j), P(j) 및 vj는 각각 ground truth, 예측, joint j에 대한 visibility를 나타낸다. 교육 중에 총 관절 수는 N = 15로 설정되었고 ground truth는 키포인트 위치에 중심인 2D 가우스를 통해 생성된다.
4. Experiments
이 섹션에서는 두 개의 대규모 벤치마크 데이터셋에 대한 실험 결과를 제공한다. PoseTrack 2017 및 PoseTrack 2018 다중 프레임 사용자 포즈 예측 챌린지 데이터셋.
4.1. Experimental Settings
Datasets
- PoseTrack은 인체 자세 예측 및 비디오의 명확한 추적을 위한 대규모 공개 데이터셋으로, 혼잡한 환경에서 고도로 은폐된 사람들의 복잡한 움직임으로 어려운 상황을 포함.
- PoseTrack 2017 데이터 세트에는 514개의 비디오 클립과 16,219개의 포즈 주석, 교육용 클립 250개, 검증용 클립 50개 및 테스트용 클립 214개가 포함.
- Pose-Track 2018 데이터셋은 비디오 클립 수를 총 1,138개 클립과 153,615개의 포즈 주석을 크게 늘림.
- 교육, 검증 및 테스트 분할은 각각 593, 170 및 375개의 클립으로 구성됩니다. 교육용 비디오 클립 중앙에 있는 30개의 프레임에는 주석이 촘촘히 붙어 있고 검증 클립의 경우 4프레임마다 주석이 제공됨.
- PoseTrack2017 및 PoseTrack2018은 모두 공동 가시성을 위한 추가 주석 레이블과 함께 15개의 조인트를 식별. 당사는 모델을 평균 정밀도(AP) 메트릭을 사용하여 visible 관절만 평가.
Parameter Settings
교육 중에 랜덤 회전, 스케일링, 자르기 및 수평 플립을 포함한 데이터 증가를 통합하여 변동을 증가. 입력 이미지 크기는 384 × 288로 고정됩니다. Fc와 Fp 또는 Fn 사이의 기본 간격은 1. 백본 파라미터는 사전 훈련된 HRNet-W48 모델 중량에 고정됩니다. 이후의 모든 체중 모수는 μ = 0 및 α = 0.001인 가우스 분포에서 초기화되는 반면 치우침 모수는 0으로 초기화됩니다. 기본 학습률이 0.0001인 Adam Optimizer를 채택하여 4epoch마다 10%씩 감소합니다. Nvidia GeForce Titan X GPU 2개를 사용하여 20개 시대에 걸쳐 32개의 배치 크기에 대한 모델을 교육.
4.2. Comparison with State-of-the-art Approaches
Results on the PoseTrack2017 Dataset
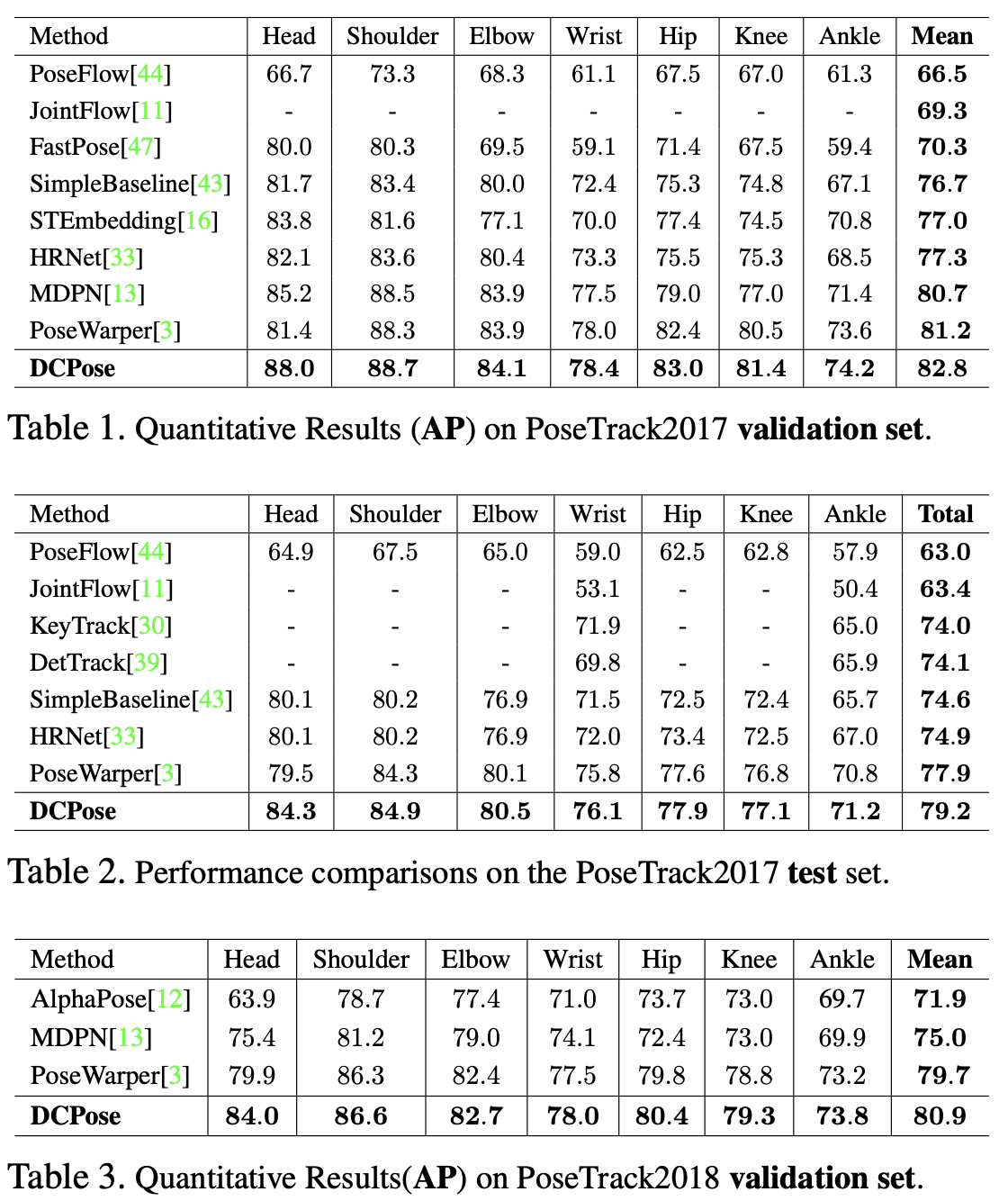
우리는 널리 채택된 평균 정밀도(AP) 지표를 사용하여 PoseTrack2017 검증 세트와 전체 테스트 세트에 대한 접근 방식을 평가. 표 1에서는 머리, 어깨, 무릎, 팔꿈치 등 주요 관절의 AP와 모든 관절의 mAP(평균 AP)를 리포트.
테스트 세트의 결과는 표 2에 나와 있다. (PoseTrack 평가 서버에 예측 결과를 업로드) DCPose는 지속적으로 기존 방법을 능가하며 mAP 79.2를 달성합니다. 비교적 어려운 관절의 성능 향상도 고무적. 손목의 경우 mAP가 76.1이고 발목의 경우 mAP가 71.2입니다. 보다 시각화된 결과는 https://github.com/Pose-Group/DCPose에서 확인할 수 있다.
Results on the PoseTrack2018 Dataset
PoseTrack2018 데이터셋에 대한 모델도 평가합니다. 검증 및 테스트 세트 AP 결과는 각각 표 3과 표 4에 표가 있습니다. 당시 소타 달성.
4.3. Ablation Experiments
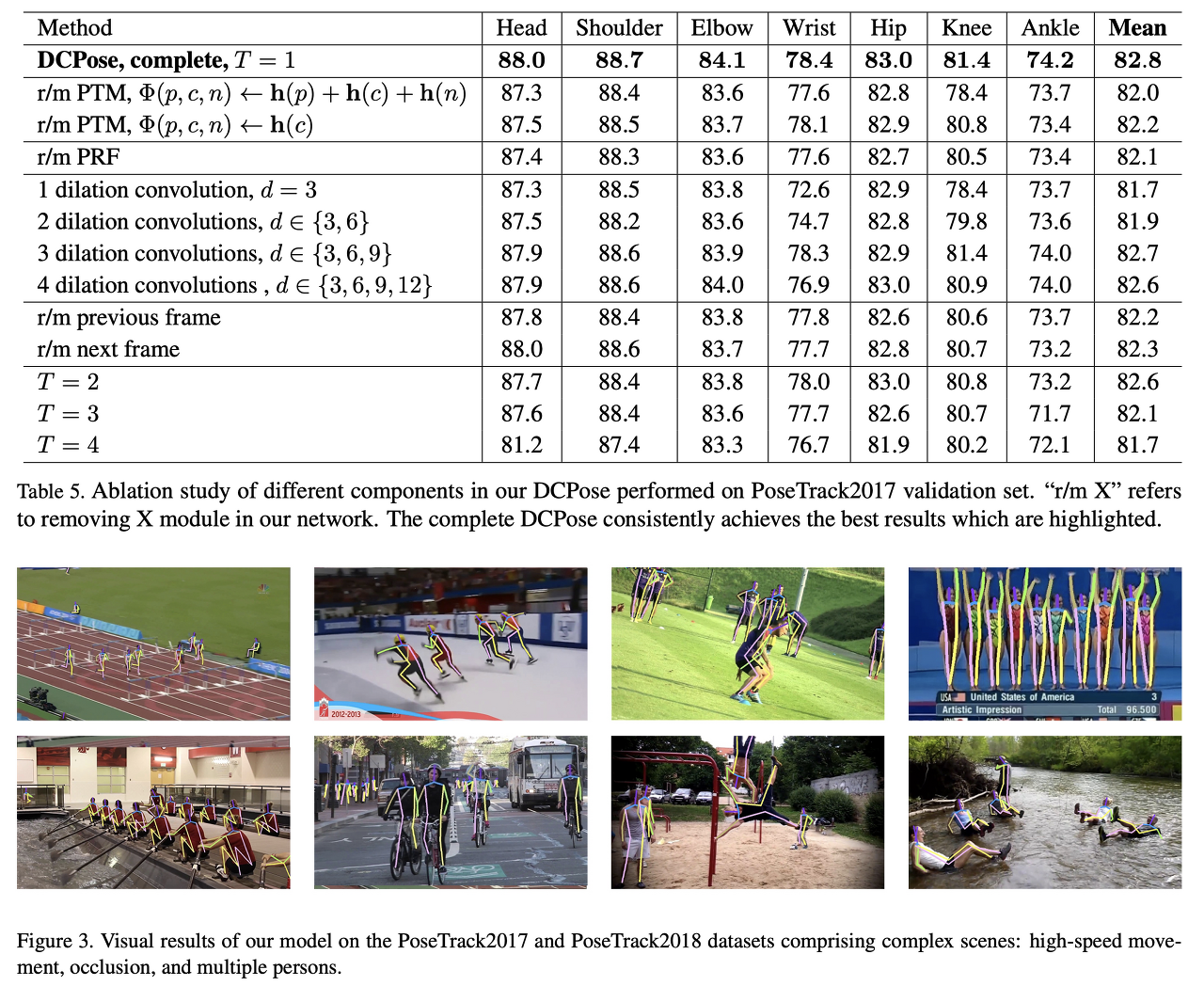
- DCPose 프레임워크에서 다양한 구성요소의 효과를 연구하기 위해 PoseTrack2017 데이터 세트에 대해 광범위한 절제 실험이 수행됩니다.
- PTM(Pose Temporal Merge), Pose Residual Fusion(PRF), Pose Correction Network 등 다양한 모듈식 네트워크를 플래팅하여 전반적인 성능에 대한 기여도를 평가.
- 또한 Fc와 Fp, Fn 사이의 프레임 간격과 같은 시간적 거리 수정의 영향뿐만 아니라 양쪽 방향의 정보를 포함할 때의 효과 조사.
Pose Temporal Merger
이 절제 설정의 경우 PTM을 제거하고 대신 다음과 같이 병합된 포즈 히트맵 Φ(p, c, n)를 얻습니다.$i) h(p) + h(c) + h(n) \xrightarrow[\text{onvolution layer}]{\text{3×3}} Φ(p, c, n); ii) h(c) → Φ(p, c, n).$ 변환 레이어 mAP는 (i)의 경우 82.8에서 82.0, (ii)의 경우 82.2로 떨어집니다. PTM 모듈을 탈거할 때 이와 같이 성능이 크게 저하된 것은 조인트에 대한 효과적인 검색 범위를 얻지 못하여 후속 포즈 보정 단계에서 조인트의 위치를 찾는 정확도가 떨어지기 때문일 수 있습니다.
Pose Residual Fusion
우리는 PRF 제거를 조사하고 3×3 식을 사용하여 pose residual maps $\Psi(p, c, n)$를 계산합니다:$h(c)−h(p)⊕h(n)−h(c) \xrightarrow[\text{onvolution layer}]{\text{3×3}} \Psi(p,c,n).$입니다. 이로 인해 mAP가 0.7에서 82.1로 떨어집니다. 이러한 성능의 대폭 감소는 오프셋을 계산하고 주요 지점 현지화를 안내하기 위한 정확한 포즈 residual 신호를 제공하는 데 있어 PRF의 중요한 역할을 강조합니다.
Pose Correction Network
우리는 PCN에서 다양한 확장 속도 세트를 채택했을 때의 효과를 연구합니다. 이것은 서로 다른 유효 수신 필드에 해당합니다. 전체 DCPose 프레임워크 설정의 경우$d=3,d∈\{3,6\},d∈\{3,6,9\}\ and\ d∈\{3,6,9,12\}$ 의 4가지 확장 설정으로 실험합니다. 반면 전체 DCPose 프레임워크 설정은 d ∈ {3,6,9,15}입니다. 표 5의 결과를 통해 확장률이 81.7 → 81.9 → 82.7 → 82.6 → 82.8에서 증가하면서 mAP가 점진적으로 개선되는 것을 관찰합니다. 이는 효과적인 수용 분야의 깊이와 범위를 증가시키는 것, 즉 확장률 범위를 변화시킴으로써 Pose Correction Network가 로컬 및 글로벌 컨텍스트를 보다 효율적으로 모델링하여 공동 위치를 보다 정확하게 추정할 수 있다는 우리의 직관과 일치합니다.

Bidirectional Temporal Input
PTM 및 PRF 입력에서 Fp 또는 Fn 중 하나를 제거하는 단일 시간 방향 제거의 효과를 조사합니다. 이전(각각 다음) 프레임 Fp(각각 Fn)를 제거할 때 mAP는 0.6(각각 0.5)이 떨어집니다. 이것은 각 방향이 비디오의 포즈 평가를 개선하는 데 도움이 되는 유용한 정보에 액세스할 수 있도록 하기 때문에 이중 시간 방향을 활용하는 것의 중요성을 강조합니다.
Time Interval
T 섹션 3에서 설명하는 시간 간격 T는 기본값이 1로 설정된 하이퍼 파라미터입니다. 즉, DCPose는 시간적 일관성에 대한 가정의 유효성을 보장하기 위해 시간/프레임 간격이 짧을수록 3개의 연속 프레임을 봅니다. 우리는 T가 2, 3, 4로 설정된 프레임 간격을 확대하는 실험을 합니다. 지수 p와 n은 p → [c - T, c) 및 n → (c, c + T]를 사용하여 랜덤하게 선택됩니다. 이 결과는 T가 증가함에 따라 성능 저하를 나타내며, T = 1의 경우 82.8에서 82.6, T의 경우 82.1,81.7로 각각 감소합니다. Fp와 Fn이 PTM과 PRF에 보다 풍부하고 효과적인 시간적, 공간적 신호를 제공할 수 있도록 프레임별 차이가 작기 때문에 이는 우리의 예상에 따른 것입니다. 반대로, 시간 간격이 길면 프레임 차이가 너무 크고 추가 단서가 효과적이지 않기 때문에 시간 일관성에 대한 가정을 무효화할 수 있습니다. 이 절제 실험에서는 연속 프레임 모델링에 대한 우리의 선택을 설명합니다. 비디오 클립의 연속 프레임은 시공간 컨텍스트의 정확한 집계를 촉진하고 우리 모델의 견고성을 향상시킵니다.
4.4. Comparison of Visual Results
정교한 시나리오에 적응할 수 있는 모델의 능력을 평가하기 위해 그림 4에서 DCPose 네트워크를 최첨단 접근 방식과 비교한 내용을 보여줍니다. 각 열은 빠른 움직임, 주변 인물, 폐색 및 비디오 디포커스 등 서로 다른 시나리오 합병증을 나타내는 반면 각 행은 서로 다른 방법의 공동 감지 결과를 표시합니다. 우리는 a) DCPose를 3가지 최신 방법, 즉 b) Simple Baseline [43], c) HRNet-W48 [33] 및 d) PoseWarper [3]과 비교합니다. NAT의 방법은 이러한 까다로운 사례에 대해 보다 강력한 탐지 기능을 제공합니다. SimpleBaseline 및 HRNet-W48은 정적 이미지에 대해 교육되어 비디오 프레임 간의 시간적 의존성을 캡처하지 못해 최적의 공동 탐지가 이루어지지 않습니다. 반면 PoseWarper는 비디오 프레임 사이의 시간 정보를 활용하여 초기 포즈 히트맵를 왜곡하지만 인접한 비디오 프레임 하나만 보조 프레임으로 사용합니다. DCPose 네트워크는 연속 프레임을 양방향 처리하여 시간 컨텍스트를 최대한 활용합니다. PTM 및 PRF 모듈의 기본 설계와 자세 감지 개선을 위한 PCN을 통해 양적, 질적으로 새로운 최첨단 기술을 구현합니다.
5. Conclusion
본 문서에서는 다중 프레임 사용자 포즈 추정을 위한 이중 연속 네트워크를 제안합니다. 이 네트워크는 벤치마크 데이터셋에서 기존의 최신 방법을 훨씬 능가합니다. Pose Temporal Merge 및 Pose Residual Fusion 모듈을 설계하여 인접 프레임에서 풍부한 보조 정보를 추출하여 위치 키포인트에 대한 지역화된 residual 보정 검색 범위를 제공합니다. 당사의 포즈 보정 네트워크는 이 검색 범위에서 포즈 추정을 세분화하기 위해 여러 개의 효과적인 수신 필드를 사용하여 주목할 만한 개선을 달성하고 복잡한 장면을 처리할 수 있습니다.




댓글