Abstract
이 논문은 단일 이미지 인간 포즈 추정에 대한 최신 결과가 다단계 컨볼루션 신경망(CNN)에 의해 달성되었음을 관찰했습니다. 정적 이미지에서 우수한 성능에도 불구하고, 비디오에서 이러한 모델을 적용하는 것은 계산 집약적일 뿐만 아니라 성능 저하와 깜박임으로 인해 어려움을 겪습니다. 이러한 차선의 결과는 주로 순차적 기하학적 일관성을 부과할 수 없고 심각한 영상 화질 저하(예: 모션 블러 및 폐색)를 처리할 수 없고 비디오 프레임 간의 시간적 상관 관계를 캡처할 수 없기 때문입니다. 본 논문에서는 이러한 문제를 해결하기 위한 새로운 반복 네트워크를 제안했습니다. 다단계 CNN에 가중치 공유 체계를 적용하면 반복 신경망(RNN)으로 다시 작성할 수 있다는 것을 보여주었습니다. 이 속성은 여러 네트워크 단계 간의 관계를 분리하여 네트워크를 비디오로 호출하는 데 있어 훨씬 더 빠른 속도를 제공합니다. 또한 비디오 프레임 간에 LSTM(Long Short-Term Memory) 장치를 사용할 수 있습니다. 이 논문은 그러한 메모리 증강 RNN이 프레임 간에 기하학적 일관성을 부과하는 데 매우 효과적이라는 것을 발견했습니다. 또한 순차적 출력을 성공적으로 안정화하면서 비디오의 입력 품질 저하를 잘 처리합니다. 실험은 이 논문의 접근 방식이 두 개의 대규모 비디오 포즈 추정 벤치마크에서 현재의 최첨단 방법을 크게 능가한다는 것을 보여주었습니다. 또한 LSTM 내부의 메모리 셀을 탐색하고 그러한 메커니즘이 비디오 기반 포즈 추정에 대한 예측에 도움이 되는 이유에 대한 통찰력을 제공했습니다.
1. Introduction
증강현실, 애니메이션, 자동 사진 편집 등 많은 분야에서 실제 응용 프로그램을 찾아내는 컴퓨터 비전에서 인체의 공동 위치를 추정하는 것은 어려운 문제입니다. 이전 방법[2, 6, 38]은 주로 잘 설계된 그래픽 모델을 통해 이 문제를 해결했습니다. 새로 개발된 접근 방식[5, 23, 36]은 심층 CNN(Convolutional Neural Networks)을 통해 더 높은 성능을 달성했습니다.
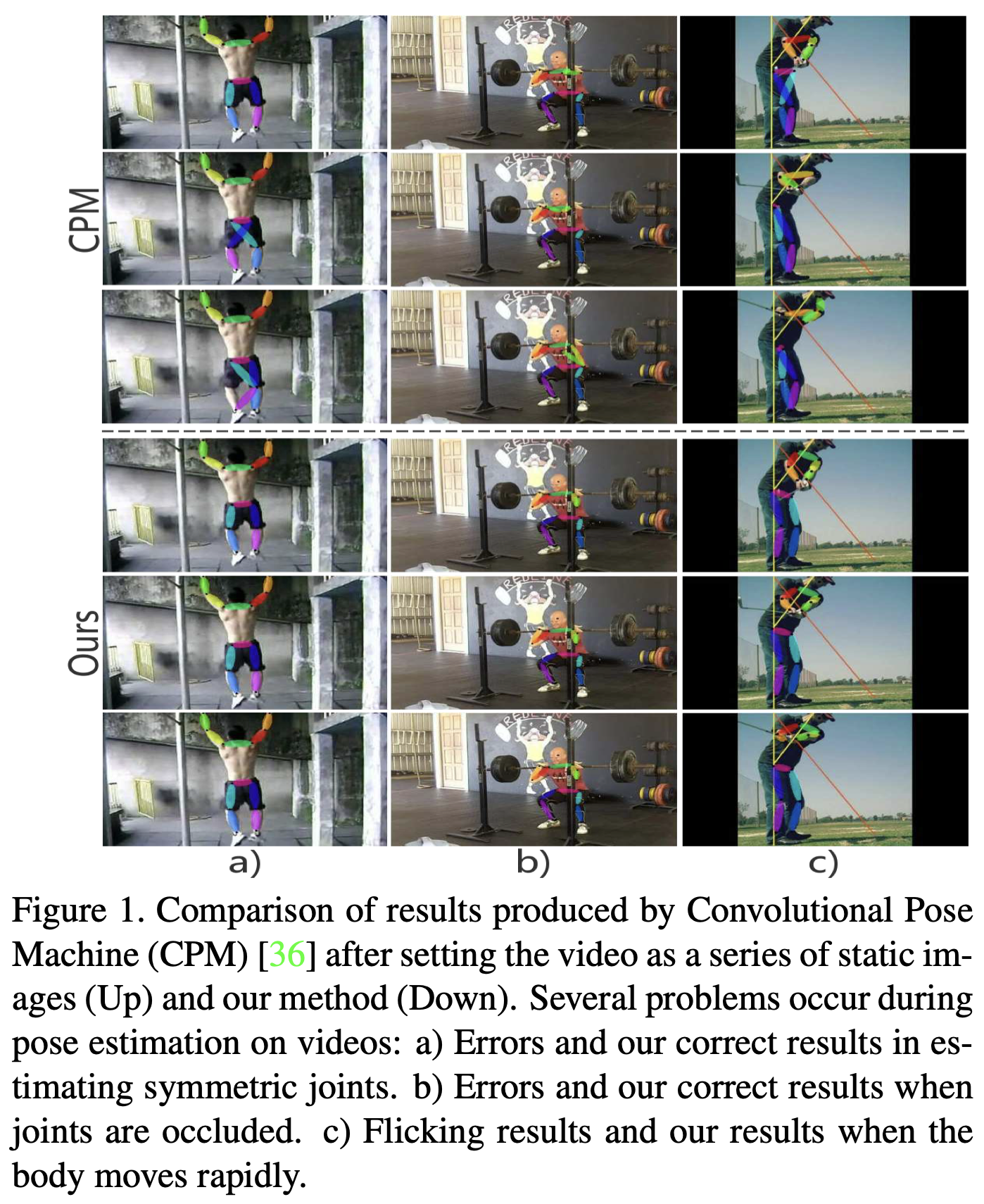
그럼에도 불구하고, 이러한 최첨단 모델들은 비디오에서의 성능을 제한하면서 스틸 이미지에 대한 훈련을 받았습니다. 그림 1은 불만족스러운 상황을 보여줍니다. 예를 들어, 기하학적 일관성이 부족하면 이전 방법은 명백한 오류를 범하기 쉽습니다. 심각한 폐색과 큰 움직임으로 인한 실수도 드물지 않습니다. 또한 이러한 모델은 대개 심층 아키텍처를 가지며 실시간 애플리케이션에 대해 계산 집약적입니다. 따라서 실시간 비디오 처리 시스템에 배포하려면 상대적으로 가벼운 모델을 사용하는 것이 좋습니다.
이러한 종류의 이상적인 모델은 비디오 프레임 간의 시간적 의존성뿐만 아니라 기하학적 일관성을 모델링할 수 있어야 합니다. 이를 해결하는 한 가지 방법은 두 프레임 사이의 흐름을 계산하고 이 추가 신호를 사용하여 예측을 개선하는 것입니다 [26, 32]. 이 접근법은 흐름을 정확하게 계산할 수 있을 때 효과적입니다. 그러나 광학 흐름 계산 시 영상 화질 저하도 발생하기 때문에 항상 그렇지는 않습니다.
본 논문에서는 이 문제를 더 잘 해결하기 위해 데이터 중심 접근 방식을 채택했습니다. 가중치 공유 체계를 적용하면 다단계 CNN이 반복 신경망(RNN)으로 다시 작성될 수 있음을 보여주었다. 이 새로운 공식은 여러 네트워크 단계 간의 관계를 분리하여 네트워크를 비디오로 호출하는 속도가 훨씬 빠릅니다. 또한 비디오 프레임 간에 LSTM(Long Short-Term Memory) 장치를 사용할 수 있습니다. 비디오 프레임 간의 시간 의존성을 효과적으로 학습함으로써, 이 새로운 아키텍처는 시간 내에 관절의 기하학적 관계를 잘 포착하고 움직이는 신체에 대한 관절 예측의 안정성을 높입니다. 이 논문은 Penn Action [40]과 subJ라는 두 개의 대규모 비디오 포즈 추정 벤치마크에서 이 논문의 방법을 평가했습니다.HMDB [14]입니다. 이 논문의 방법은 성능과 속도 모두에서 이전의 모든 방법을 크게 능가했습니다.
또한 조사 결과를 정당화하기 위해 LSTM 내부의 메모리 셀 내부 역학 관계를 조사하고 LSTM 장치가 비디오 포즈 추정 성능을 향상시키는 이유와 방법을 설명했습니다. 메모리 셀이 시각화되었고 통찰력이 제공되었습니다.
이 논문의 기여는 다음과 같이 요약할 수 있습니다.
- 먼저 LSTM과 함께 새로운 반복 아키텍처를 구축하여 포즈 추정을 위한 비디오 프레임 간의 시간적 기하학적 일관성과 의존성을 포착했습니다. 이 논문의 방법은 두 개의 대규모 벤치마크에서 기존의 모든 접근 방식을 능가했습니다.
- 둘째, 새로운 아키텍처는 네트워크 단계 간의 관계를 분리하여 비디오에 대한 추론 속도가 훨씬 빠릅니다.
- 세 번째, LSTM 메모리 셀을 조사하여 비디오의 공동 예측을 개선하는 데 어떤 도움이 되는지 시각화했습니다. 통찰력을 제공하고 결과를 정당화합니다.
2. Related works
단일 이미지 포즈 추정에 대한 초기 연구는 관절 사이의 관계를 모형화하기 위한 그래픽 구조[2, 6, 28, 33, 38]를 구축하는 것에서 시작되었습니다. 그러나 이러한 방법은 실제로 다양한 인간의 자세에 따라 일반성을 제한하는 수작업 기능에 크게 의존합니다. 이러한 방법의 성능은 최근 CNN 기반 방법에 의해 능가되고 있습니다 [4, 5, 23, 34, 35, 36]. 이러한 심층 모델은 데이터에서 다양한 공간 관계를 학습함으로써 보이지 않는 장면에서 일반화할 수 있는 능력을 가지고 있었습니다. 최근 작품[23, 36]은 각 네트워크 단계의 출력을 반복적으로 개선하는 전략을 채택하여 많은 이미지 기반 벤치마크에서 최첨단 결과를 달성했습니다. [3]에서는 훈련 매개 변수를 줄이기 위해 반복 모델이 제안되었지만 비디오가 아닌 이미지를 위해 설계되었습니다.
기존 이미지 기반 방법을 비디오 시퀀스에 직접 적용하면 차선책이 됩니다. 크게 두 가지 문제가 있습니다. 첫째, 이러한 모델은 비디오 프레임 간의 시간적 의존성을 포착하지 못했으며 기하학적 일관성을 유지할 수 없었습니다. 이미지 기반 모델은 모션 흐림과 폐색에 쉽게 시달릴 수 있으며 일반적으로 인접 프레임에 대해 일관되지 않은 결과를 생성할 수 있습니다. 둘째, 이미지 기반 모델은 일반적으로 매우 깊고 계산 비용이 많이 듭니다. 실시간 응용 프로그램에서 이를 채택할 경우 문제가 발생합니다.
이전의 몇 가지 연구는 시간적 단서를 포즈 추정에 통합했습니다 [8, 12, 19, 24, 26, 27, 32]. Modep[12]은 처음에 ConvNet과 Pfister 등에 모션 기능을 병합하려고 했습니다. [27]은 다른 컬러 채널에 연속적인 프레임을 입력으로 삽입하는 창의적인 시도를 했습니다. 이후 작품[26, 32]에서는 프레임 간에 움직임이 원활하도록 예측된 위치를 조정하기 위해 조밀한 광학 흐름[37]을 생성 및 사용했습니다. 광학 흐름과 공간-시간적 모델의 조정에 모두 의존하는 Thin-Slicing Network[32]에 의해 좋은 결과가 달성되었습니다. 그러나 이 시스템은 계산 집약적이며 이전 이미지 기반 방법보다 느립니다. 이 논문의 방법은 시간적 종속성을 포착할 수 있는 단순 반복 아키텍처인 체인드 모델[8]과 유사합니다. [8]과 달리, 이 논문의 모델은 메모리 증강 RNN(LSTM)에 의한 시간 의존성을 더 잘 포착하여 더 나은 성능을 달성했습니다. LSTM은 동작 추적 및 동작 인식과 같은 포즈 관련 작업에서 널리 사용되어 왔습니다 [7, 13, 20, 22]. RPSM[19]도 3D 공간에서 포즈 추정을 위해 LSTM을 채택했지만, LSTM은 2D와 3D 변환 사이의 영역에서 작동했고 그러한 변환의 품질에 주로 신경을 썼습니다. LSTM을 2D 비디오 기반 포즈 추정에 사용함으로써, 이 논문은 간결한 아키텍처를 유지하면서 현재의 최첨단 방법을 능가할 수 있습니다.
신경 네트워크가 뒤에 내부 메커니즘을 이해하는 것과 많은 연구원들 사이에서 큰 관심을 중요하다.몇몇 작품은 꼬임 선 모델 원래 이미지로 형상을 재현해에 의해 배웠던 것을 설명하기 위한 것[21, 39].마찬가지로,[17]은 장기 상호 작용 텍스트 처리에 반복되는 신경 네트워크에 의해 포획된 공부를 했다.그리고 특히, LSTM의 텍스트 기반 작품에 기능 해석했다.
3. Analysis and Our Approach
3.1. Pose Machines: From Image to Video
포즈 머신[29]은 순차적으로 관절 위치를 예측하는 방법으로 처음 도입되었습니다. 이 모델은 신체 부위 간의 강력한 상호 연결을 학습하기 위해 추론 기계 프레임워크에 구축되었습니다. Convolutional Pose Machine(CPM) [36]은 심층 아키텍처에서 구현한 포즈 머신으로부터 아이디어를 이어받았습니다. 동시에, 시스템 끝에 예측된 열 지도를 제작하여 완전한 컨볼루션 설계를 채택했습니다. 포즈 머신에서 활용되는 중요한 전략으로, 이전 신념을 다음 단계로 전달하고 모든 단계에서 손실을 감독하는 것은 그레이디언트 소멸 문제를 해결함으로써 그러한 심층 ConvNet의 훈련에 도움이 됩니다. [36]의 설명에 따라, 다음과 같은 방법으로 모델을 수학적으로 공식화할 수 있습니다: $bs,RW×H×(P+1)b_s , RW × H× (P +1)$ (P 조인트 + 크기가 W × H인 하나의 background channel)을 단계 $s∈{1,2,....,S}s ∈ \{1, 2, ...., S\}$의 belief 으로 나타내며, 그것들은 반복적으로 계산될 수 있습니다.
여기서 $ X∈RW×H×CX ∈R^{W×H×C} $는 모든 단계로 전송되는 원본 이미지입니다. Fs(·)는 입력 이미지에서 중요한 기능을 추출하는 데 사용되는 ConvNet입니다. 이러한 기능은 이전 beliefs(즉, bs-1)과 연결되어 다른 ConvNets g(·)로 전송되어 정교한 belief map을 생성합니다. Gs(·)와 Fs(·)는 동일한 아키텍처(사실=1(·)를 공유하더라도 포즈 추정에 큰 역할을 하는 것은 쉽게 알 수 있습니다. Gs(·)와 Fs(·)는 동일한 아키텍처를 공유하지만 여러 단계에서 동일하지 않기 때문에 CPM이 포즈 추정에 큰 역할을 한다는 것을 쉽게 알 수 있습니다. (사실 gs=1(·)는 gs>1(·)와 비교하여 더 깊은 구조를 사용합니다. 이는 처리되지 않은 입력에 로컬 증거만 포함되므로 추가 개선을 위한 보다 정밀한 confidence maps을 만들기 위해서입니다.) 각 단계 끝에 중간 감독을 추가하여 신뢰도를 반복적으로 수정합니다. 그러나 비디오 기반 포즈 추정에 이 심층 구조를 적용하는 것은 시간적 정보를 통합하지 않기 때문에 실용적이지 않습니다.
체인드 모델 [8]은 이 문제에 대한 RNN 스타일 모델을 구성할 동기를 제공했습니다. 그리고 CPM의 설계에 영감을 받아 CPM을 반복 CPM으로 개편했습니다. Eq. (1)을 참조하여 CPM이 여러 단계에 걸쳐 두 함수 gs(·)와 Fs(·)의 가중치를 공유함으로써 반복 구조로 쉽게 변환될 수 있음을 발견했습니다. 수학적으로, CPM에서 파생된 새로운 반복 포즈 머신은 다음과 같이 공식화될 수 있습니다.
여기서, bt는 Eq. (1)에서 설명한 것처럼 더 이상 특정 단계의 믿음 맵이 아니지만, 그것은 프레임 t { {1, 2, ......, T}과 일치하는 생성된 믿음 맵을 나타냅니다. 여기서 T는 이제 이 비디오에서 프레임 길이입니다. 입력 $$Xt(1≤t≤T)X_{t(1\leq t\leq T)}$$는 서로 다른 단계에서 동일하지 않지만 비디오 시퀀스의 연속 프레임입니다. 마찬가지로, 초기 위치의 g0(·)은 여전히 g(·)와 다르며, 이제 모든 다음 단계는 정확히 동일한 기능을 공유합니다. 이 구현으로 모델은 반복 설계로 재구성되며 가변 길이 비디오에서 관절 위치를 예측하는 데 사용할 수 있습니다. 반복 특성을 제외하고, 단일 프레임에서 위치를 예측하는 매개 변수를 줄이는 또 다른 주목할 만한 성과도 달성합니다.
Eq. (2)에서 설명한 모델의 훈련은 이제 일련의 연속적인 프레임에서 일괄적으로 진행될 수 있습니다. 그러나 이 RNN 모델은 비디오 기반 포즈 추정에서 최적의 성능을 달성할 수 없습니다. 특수 게이트 설계와 메모리 구현으로 인해 LSTM 유닛[10]을 포함하는 것이 유익하다는 것을 발견했습니다. 이 수정은 Eq. (2)를 추가로 적용함으로써 이루어질 수 있습니다. 다시 말해서, 이 논문의 새로운 기억 가능 반복 포즈 기계는 다음과 같습니다.
L(·)는 메모리의 유입 및 유출 절차를 제어하는 함수입니다. Eq. (2)에서 g0(·)은 feature 인코더와 예측 생성기의 두 부분을 포함합니다. L(·)는 처리된 feature을 직접 수신하므로 Eq.(3)와 같이 이 두 부품을 분리하고 LSTM을 서로 연결합니다. 추출기는 다른 단계에서 F(·)와 같이 동작하지만 훨씬 더 깊기 때문에 F'(·)로 표시합니다. 이제 생성자 g(·)가 모든 단계에서 동일하다는 것도 확인할 수 있습니다. 첫 번째 단계에서 LSTM의 메모리에 아무것도 없기 때문에, L(·)은 이후 단계에서 그것과 약간 다르겠지만, 그들은 모두 유사한 기능을 수행합니다. 구현에 대해서는 이후 섹션에서 자세히 논의할 것이며, 더 중요한 것은 LSTM이 반복 포즈 머신의 성능을 강력하게 향상시킬 수 있는 방법에 대해 설명할 것입니다.
3.2. LSTM Pose Machines
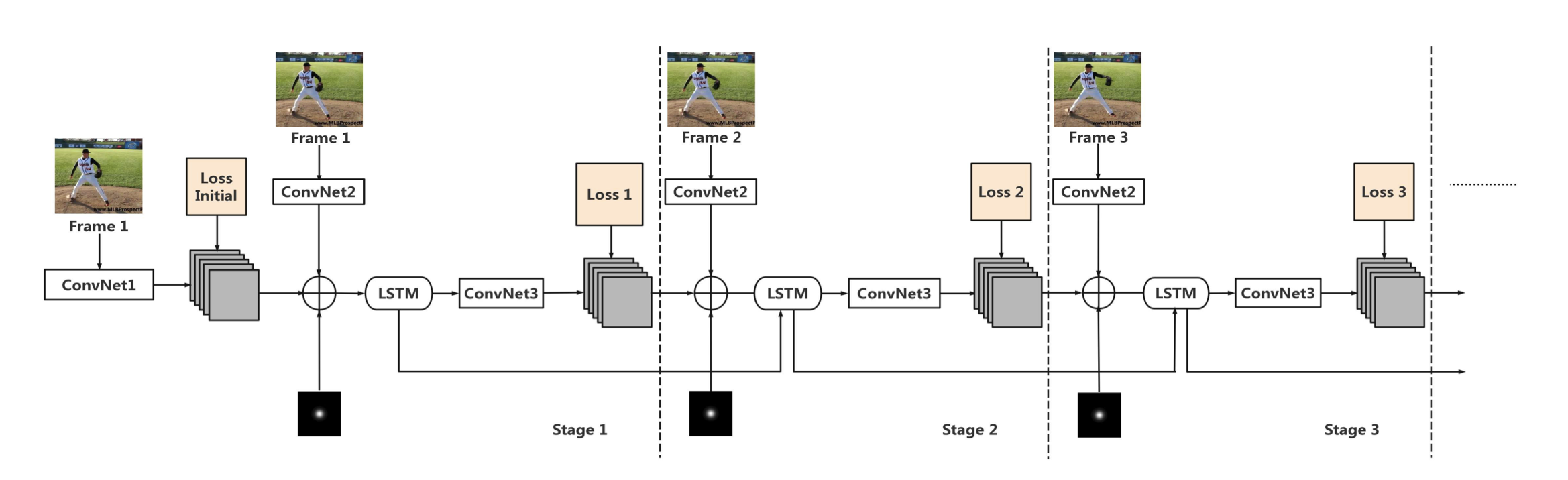
- This network consists of T stages, where T is the number of frames.
- In each stage, one frame from a sequence will be sent into the network as input.
- ConvNet2 is a multi-layer CNN network for extracting features while an additional ConvNet1 will be used in the first stage for initialization.
- Results from the last stage will be concatenated with newly processed inputs plus a central Gaussian map, and they will be sent into the LSTM module.
- Outputs from LSTM will pass ConvNet3 and produce predictions for each frame.
- The architectures of those ConvNets are the same as the counterparts used in the CPM model [36] but their weights are shared across stages. LSTM also enables weight sharing, which reduces the number of parameters in our network.
Details of the Model. 그림 2는 비디오에서의 포즈 추정을 위해 Eq. (3)에 명시된 구조를 보여줍니다. 동일한 비디오 클립의 연속된 프레임은 서로 다른 단계의 입력으로 네트워크로 전송됩니다. 그림에서와 같이, t = 1, F²(Xt)는$𝑭’(𝑿𝒕)⇒𝑭𝟎(𝑿𝒕)⊕𝑭(𝑿𝒕)𝑭’(𝑿_𝒕 )⇒ 𝑭_𝟎 (𝑿_𝒕) ⊕ 𝑭(𝑿_𝒕)$로 분해될 수 있는 데, 여기서 F0(·)은 원시 입력을 처리하는 것을 목표로 하는 ConvNet1이고 F(·)는 모든 단계에서 일관되게 사용되는 인코더 ConvNet2입니다. F0(·)은 첫 번째 프레임과 관련된 예비 믿음 맵을 생성합니다. 예측은 신뢰 수준이 높지 않기 때문에 F(X1)와 다시 연결되어 보다 정확한 결과를 생성합니다. LSTM은 이 아키텍처에서 가장 중요한 구성요소입니다. 위에서 언급한 L(·) 함수라고 할 수 있습니다. 실제로 이전 메모리를 잊고 새로운 정보를 흡수하고 출력을 생성하는 데는 여러 단계가 필요합니다. ConvNet3은 Eq. (3)에서 설명한 생성기 g(·)이며 LSTM의 출력에 연결됩니다. 이러한 모든 ConvNet 세그먼트는 여러 컨볼루션 계층, 활성화 계층 및 풀링 계층으로 구성됩니다. 그들은 컨볼루션 포즈 머신[36]의 설계를 이어받으며, 그것들의 구조는 CPM 모델에 사용된 것과 동일합니다. 차이점은 모델이 여러 단계에서 이러한 모든 구성 요소에 대한 가중치 공유를 허용한다는 것입니다. CPM [36]에 이어 더 나은 성능을 위해 입력 연결 중에 중앙 가우스 피크를 포함하는 슬라이스를 추가합니다. 드롭아웃은 ConvNet1의 마지막 레이어에도 포함됩니다.
Convolutional LSTM Module. LSTM의 구조와 기능은 많은 이전 연구에서 논의되었다[10, 9, 31]. 바닐라 LSTM은 [9]에 정의되며 가장 일반적으로 사용되는 LSTM 구현이다. [9]에서 Greff 등은 LSTM의 구성요소에 대한 포괄적인 연구를 수행했으며, 그들은 망각 게이트, 입력 게이트 및 출력 게이트를 가진 이 바닐라 LSTM이 이미 LSTM의 다른 변형보다 성능이 우수하다는 것을 발견했다. Eq. (4)는 반복 모델에서 사용한 바닐라 LSTM 유닛 내부의 작동을 보여준다.
기존의 LSTM과 달리, 여기서 '*'는 행렬 곱셈이 아니라 [31] 및 [18]과 유사한 컨볼루션 연산을 가리킨다. 결과적으로, Eq. (4)의 모든 '+'는 요소별 추가를 나타낸다. 여기서 e'는 bias term를 나타냅니다. 이러한 설정은 이 논문의 컨볼루션 LSTM 설계의 결과를 초래한다. it(·), ft(·), ot(·)는 각각 입력 게이트이며, forget 게이트와 출력 게이트이다. 마지막 단계 ht-1의 새로운 입력 Xt와 숨겨진 상태에 의해 상호 제어된다. Xt here는 Eq.(3)와 동일하지 않습니다. 여기에는 이미 연결된 입력(즉, Eq. (3)의 F(Xt)⊕bt-1)이 있다. 관문의 컨볼루션 설계는 글로벌 정보보다는 지역 맥락에 더 초점을 맞추고, 소규모 지역에서의 관절 변화에 더 많은 관심을 기울인다. 3 × 3 커널을 가진 하나의 컨볼루션 계층이 성능에 가장 적합한 것으로 밝혀졌다. Ct는 오래된 기억을 잊어버리고 새로운 정보를 지속적으로 받아들임으로써 장기적으로 지식을 보존하는 메모리 셀이다. hidden state ht는 새로 형성된 메모리에서 출력되고 생성기(·)를 통해 현재 신념을 생성하는 데 사용됩니다. 첫 번째 메모리 셀 C1은 잊기 작업을 사용할 수 없기 때문에 i1 ⊙ g1로 계산됩니다.
Training of the Model. LSTM 포즈 기계는 카페[15]에서 구현되며 LSTM의 기능은 컨볼루션 및 요소별 연산에 의해 간단히 구현된다. 데카르트 좌표의 라벨은 관절 위치에 가우스 피크가 중앙에 있는 heat map로 변환된다. 네트워크에는 T 스테이지가 있으며, 여기서 T는 훈련 시퀀스의 연속 프레임 수입니다. 각 단계 끝에 손실이 추가되어 주기적으로 학습을 감독합니다. 훈련은 모든 관절과 모든 프레임에 대한 예측과 ground truth 사이의 총 l2 거리를 줄이는 것을 목표로 한다. 손실 함수는 다음과 같이 정의됩니다.
여기서 bt(p)는 생성된 믿음이고 g.t.t(p)는 part pin stage t에 대한 ground truth heat map이다.
4. Experiments and Evaluations
이 섹션에서는 널리 사용되는 두 데이터 세트에 대한 실험과 정량적 결과를 제시한다. 이 논문의 방법은 둘 다 최첨단 결과를 얻었습니다. 이 부분에서는 질적인 결과도 제공될 것입니다. 마지막으로 LSTM 유닛 내부의 역학 관계를 탐색하고 시각화할 것입니다.
4.1. Datasets Penn Action Dataset. Penn Action Dataset [40]은 총 2326개의 비디오 클립이 포함된 대규모 데이터 세트이며, 교육용 클립은 1258개, 테스트용 클립은 1068개입니다. 평균적으로 각 클립에는 70개의 프레임이 포함되어 있지만, 실제로 개수는 경우에 따라 많이 다릅니다. 머리, 어깨, 팔꿈치, 손목, 엉덩이, 무릎, 발목 등 13개의 관절이 모든 프레임에 주석을 달고 있습니다. 추가 레이블은 단일 영상에 조인트가 표시되는지 여부를 나타냅니다. 이전 작업에 이어 가시적인 조인트에 대해서만 평가가 실시됩니다.
Sub-JHMDB Dataset. JHMDB[14]는 포즈 추정을 위한 또 다른 비디오 기반 데이터 세트입니다. 비교를 위해, 이전 연구와 일관성을 유지해 하위 JHMDB 데이터 세트라는 JHMDB 하위 집합에 대해서만 실험을 수행합니다. 이 부분 집합에는 완전한 본체만 포함되고 보이지 않는 조인트는 주석을 달지 않습니다. 하위 JHMDB는 3개의 다른 분할 체계를 가지고 있으므로 모델을 별도로 교육하고 이 3개의 분할에 대한 평균 결과를 보고했습니다. 이 부분 집합에는 316개의 클립이 있으며 모든 11200 프레임이 동일한 크기로 표시됩니다. 분할 결과는 대략 3과 같은 열차/시험 비율이 됩니다.
4.2. 구현 세부 정보 Data Augmentation대는 입력의 변동을 증가시키기 위해 랜덤하게 수행됩니다. 프레임 집합이 동시에 네트워크로 전송되므로 변환은 패치 내에서 일관됩니다. 이미지의 배율은 인자에 의해 랜덤하게 조정됩니다. 펜의 경우 이 인자는 0.8에서 1.4 사이이고 하위 JHMDB의 경우 본체가 원래 더 작기 때문에 1.2에서 1.8 사이입니다. 그런 다음 영상이 [-40º,40º] 정도로 회전하고 무작위성으로 플립됩니다. 마지막으로 모든 영상이 고정된 크기(368 × 368)로 자르고 본체가 중앙에 설정됩니다.
Parameter settings. Convolutional Pose Machines [36]의 아키텍처를 직접 수정했으므로 사전 훈련된 CPM 모델을 기반으로 가중치를 쉽게 초기화할 수 있습니다. 먼저 비디오 시퀀스에 대해 훈련된 모델과 동일한 구조를 사용하는 단일 이미지 모델을 제작했습니다. 차이점은 이 단일 영상 모델에 대해 T = 6을 설정하고 모든 단계에서 입력이 동일하다는 것입니다. 모델의 가중치는 여러 단계에서 공유할 수 있기 때문에 CPM 모델의 처음 두 단계에서 가중치를 복사했습니다. 이 모델은 LSP[16]와 MPII[1] 데이터 세트의 조합에 대해 여러 시기에 걸쳐 미세 조정되었으며, 이는 처음부터 CPM 모델을 훈련시키기 위한 동일한 데이터 소스입니다.
Penn 및 Sub-JHMDB에 대한 교육을 위한 모델은 위에서 설명한 단일 이미지 모델에서 가중치를 복사하는 것으로 시작되었습니다. 교육 중에 반복 모델의 길이는 5(즉, T =5)로 설정되며, 비디오 시퀀스에서 충분한 변화를 관찰할 수 있을 만큼 큽니다. 운동량이 0.9이고 체중 감량이 0.0005인 확률적 경사 하강은 학습 과정을 최적화하는 데 사용됩니다. 배치 크기를 4로 선택했습니다. 초기 학습 속도는 8 × 10-5로 설정되며, 40 k 반복마다 0.333의 인자를 곱하면 감소합니다. 그라데이션 클리핑이 사용되며 그라데이션 폭발을 방지하기 위해 100으로 설정됩니다. 첫 번째 단계에서 탈락 비율은 0.5입니다.
4.3. Evaluation on Pose Estimation Results
이전의 많은 작품들과 유사하게, 관절에 대한 믿음은 각 단계가 끝날 때 만들어집니다. 그런 다음 x,y 좌표의 위치를 최대 신뢰도를 찾는 것에서 보간할 수 있습니다. 테스트하는 동안, 이 논문은 먼저 입력의 크기를 다른 크기로 조정하고, 보다 신뢰할 수 있는 믿음을 만들기 위해 출력을 평균했습니다. 실험에서, 이미지를 7개의 척도로 재확대했고 스케일링 인자는 훈련 중 증대에 사용한 해당 영역 내에 있습니다. 결과를 평가하기 위해 [38]에 도입된 PCK metri을 채택합니다. 추정치가 실제 위치에서 α·max(h, w) 이내에 있으면 정확한 것으로 간주됩니다. 여기서 손은 경계 상자의 높이와 너비입니다. 다른 방법과 일관되게 비교하기 위해, α는 두 데이터 세트에 대한 평가를 위해 0.2로 선택되었습니다. 펜은 이미 각 영상 내의 경계 상자에 주석을 달지만 하위 JHMDB의 경계 상자는 분할에 사용되는 꼭두각시 마스크에서 추론됩니다.
4.4. Analysis of Results

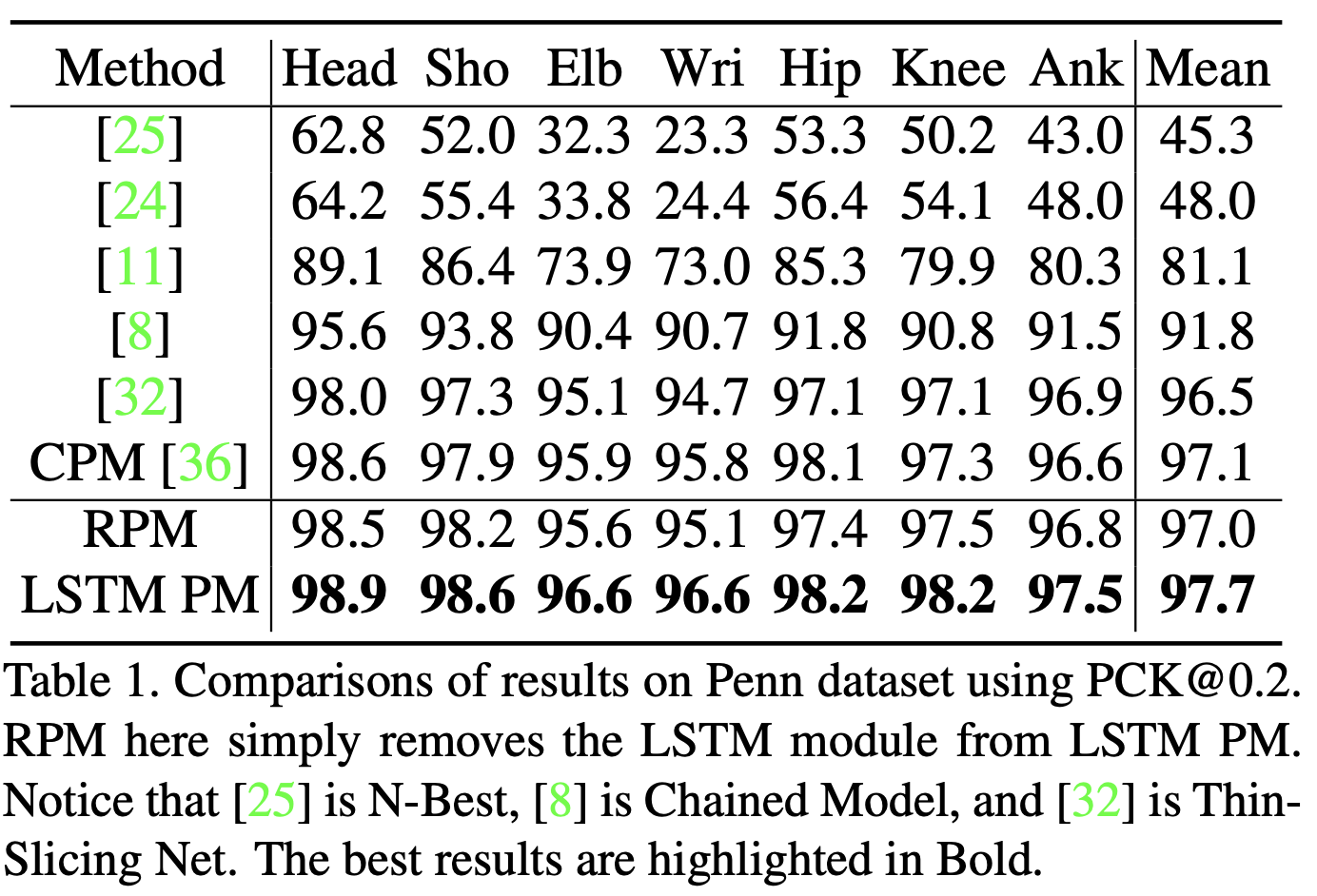
Results on Penn and sub-JHMDB. 표 1과 표 2는 펜 데이터 세트와 하위 JHMDB 데이터 세트에 대한 모델 및 이전 작업의 성능을 보여줍니다. Eq. (3)에 명시된 LSTM 포즈 머신(LSTM PM)과는 별도로, Eq. (2)에 설명된 대로 단순화된 반복 포즈 머신 모델(RPM)도 제시합니다. 간단히 LSTM 모듈을 제거하고 LSTM 구성 요소의 기여도를 연구하기 위해 동일한 파라미터를 사용하여 교육했습니다. 모델에서 장기적인 시간적 정보를 고려함으로써 두 벤치마크에서 모두 개선된 결과를 얻었습니다. Seagate의 최첨단 LSTM 포즈 머신을 Thin-Slicing Net[32]과 같은 이전의 비디오 기반 포즈 추정 방법과 비교하면, 펜 벤치마크의 경우 모든 신체 부위에 고르게 분포하는 1.2%의 전반적인 개선을 관찰합니다. 그 모든 부분들 중에서, 1.9% 증가의 가장 큰 부상이 손목에서 온다는 것을 발견했습니다. 마찬가지로 서브JHMDB 데이터 세트의 경우 거의 모든 접합 부분에서 개선을 달성했습니다. 가장 큰 증가는 팔꿈치와 손목에서 나온다는 것을 알아챌 가치가 있습니다. 이것은 급격한 움직임과 폐색에 노출되는 관절의 예측 정확도를 강하게 향상시켰기 때문에 중요한 결과입니다. 실험에서, 동일한 훈련 계획으로 이 두 데이터 세트에 대한 CPM 모델[36]도 훈련했습니다. Qualitative 결과는 그림 3에 나와 있습니다. 이 논문의 방법이 강력한 예측 능력을 통해 프레임 간의 큰 변화에 대처하는 데 특히 적합하다는 것을 알 수 있습니다. 비록 몸이 움직이고 있거나 비디오 중간에 끼어 고생하고 있지만, 그들의 과거 궤적을 통해 위치를 부드럽게 추론할 수 있습니다.
Contribution of LSTM Module. 표 1과 표 2에서 LSTM 모듈(RPM)이 없는 반복 모델도 이전의 모든 비디오 기반 방법에 비해 개선된 결과를 제공했음을 알 수 있습니다. CPM은 이미지 기반 포즈 추정의 강력한 기준이며 다단계 미세화를 사용하여 공동 위치를 추론합니다. RPM은 짧은 구조를 사용하는 동안 비디오 기반 작업에서 필수적인 임시 정보를 활용합니다. 실험에 따르면 RPM은 시간 상관 관계를 최적의 방식으로 활용하지 않기 때문에 RPM이 CPM을 엄격하게 능가하지 않습니다. 기억 증강 반복 모델은 시간적 정보를 더 잘 포착하고 두 가지를 모두 능가합니다. RPM과 비교하여, LSTM 모델은 PEN에서 0.7%, 서브JHMDB에서 1.4%의 평균 증가를 달성합니다. 헤드, 숄더 및 힙과 같은 쉬운 부품의 경우, RPM은 이미 양호한 성능을 발휘할 수 있습니다. 그러나 쉽게 폐색되거나 움직일 수 있는 관절의 경우, 기억 세포는 과거의 위치를 더 잘 활용함으로써 관절의 추정 정확도를 강력하게 촉진하도록 돕습니다. LSTM 모듈의 도움으로, 접근 방식이 움직이는 프레임으로부터 관절을 예측하는 전반적인 안정성을 증가시켰다고 결론 내릴 수 있습니다.
Analysis of increasing the iterations of LSTM 이 파트에서는 여러 반복 T를 사용할 때의 효과를 살펴봅니다. 하위 JHMDB 데이터 세트에서 서로 다른 단계 수, 즉 T=1, 2, 5, 10으로 모델을 교육하고 실험 결과를 표 3에 보고합니다. LSTM에서 한 번의 반복만 있을 경우, CPM 모델과 같은 시간적 정보나 정교한 작업이 없기 때문에 성능이 CPM보다 훨씬 더 떨어집니다. 반복 횟수가 2회로 증가하면 성능이 현저하게 향상되는데, 현재 프레임은 마지막 단계부터 거의 정적인 관절에 대한 정보를 유지하고, 단지 더 빠르게 움직이는 관절만 학습할 수 있기 때문입니다. 비디오 프레임 중에서 선호도가 더 안정적입니다. 더욱이, 2에서 5까지의 반복을 추가할 때 성능은 여전히 증가하는데, 이는 장기적인 시간적 정보가 비디오 포즈 추정에 좋다는 것을 의미합니다. 그러나 반복 횟수가 많을수록 성능이 높아지는 것은 아닙니다. T=10의 실험은 현재 프레임보다 훨씬 이전인 프레임 정보가 무력하다는 것을 알려줍니다. 성능과 훈련 계산 소비량의 균형을 맞추기 위해 T=5를 설정했습니다.
4.5. Inference Speed
추론 시간은 실시간 애플리케이션에 매우 중요합니다. 이전 방법은 단일 프레임에 대해 여러 단계를 거쳐야 하기 때문에 결과를 생성하는 데 비교적 많은 시간이 소요됩니다. 모든 비디오 프레임에 대해 단일 단계만 거치면 되기 때문에 이전의 다단계 CNN 기반 방법보다 훨씬 더 빠르게 작동합니다. 첫 번째 프레임의 경우 시작하기 위해 더 긴 단계를 거쳐야 합니다. 공정한 비교를 위해, 무작위로 100프레임의 동영상을 선택하여 CPM 모델과 당사 모델에 각각 전송하여 테스트합니다. 실험 결과에 따르면 CPM 모델은 프레임당 48.4ms가 필요하지만, 프레임당 25.6ms만 필요합니다. 즉, 모델은 CPM 모델보다 약 2배 더 빨리 작동합니다. CPM을 기반으로 플로우 맵을 생성해야 하는 Thin-Slicing Net[32]과 같은 흐름 기반 방법과 비교하면 속도 면에서 모델의 장점이 더 큽니다. 따라서 모델은 특히 실시간 비디오 기반 포즈 추정 애플리케이션에 선호됩니다.
4.6. Exploring and Visualizing LSTM
LSTM 뒤에 있는 메커니즘을 더 잘 이해하기 위해, 메모리의 내용을 탐구하는 것은 실질적인 단서를 제공합니다. 샤르마 외. [30]과 리 외. [18] 최근에 관련 문제에 대한 시도를 했습니다. 작품에서는 각 단계마다 정적인 관심에 더 초점을 맞췄지만, 위치가 바뀌면서 생기는 메모리 콘텐츠의 전환을 다루려고 합니다.
그림 4는 탐사 결과를 보여줍니다. 먼저 메모리에 있는 채널들을 샘플링하여 원래의 이미지 공간에 다시 매핑했습니다. 설정에 따라 각 메모리 셀에는 48개의 채널이 있으며 여기서는 시각화를 위해 몇 가지 대표적인 채널만 선택했습니다. 그림에서, 다른 채널에서의 기억들이 다른 부분에 대한 관심이라는 것을 알 수 있습니다. 그 중 일부는 트렁크나 가장자리(처음 세 개의 샘플)에 대한 글로벌 뷰이며, 일부는 특정 관절에 초점을 맞춥니다(다른 세 개는 팔꿈치, 엉덩이 및 머리에 대한 메모리 주의를 보여줍니다). 이러한 메모리는 네트워크에서 선별적으로 출력되고 추정을 위해 처리된다는 점을 기억하십시오. 따라서 전역 정보와 로컬 정보가 모두 포함된 메모리 셀은 단일 프레임에서 공간적으로 상관된 관절을 예측하는 데 도움이 됩니다.

- 그림 5. LSTM의 메모리 a)memory from last stage (i.e. Ct−1) on last frame Xt−1,
- b)memory from last stage (i.e. Ct−1) on new frame Xt,
- c)memory after forget operation (i.e. ft ⊙ Ct−1) on new frame Xt ,
- d)newly selected input(i.e. it ⊙ gt) on new frame Xt,
- e)newly formed memory (i.e. Ct) on new frame Xt, which is the element-wise sum of c) and d)
- f)the predicted results on new frame Xt. For each samples we pick three consecutive frames.
LSTM의 더 중요한 특성은 유용한 사전 정보와 새로운 지식을 모두 사용하여 메모리를 유지한다는 것입니다. Eq. (4)에서 설명한 것처럼 LSTM은 각 반복 동안 잊고 기억하는 과정을 거칩니다. 그림 5의 각 행에는 한 번의 반복 내에서 메모리 셀의 여러 단계가 나와 있습니다. 반복 내에서 LSTM의 진화를 캡처합니다(선택된 채널 하나만 표시됨). 각 열은 그림 설명에 따라 단일 위상을 나타냅니다. 첫 번째 샘플에서 잊기 연산은 세 개의 연속 프레임(col.3)에서 거의 정적인 손목과 머리와 같은 다음 단계의 예측을 위해 유용한 정보를 선택적으로 보존하는 반면, 이 단계의 새로운 입력은 무릎과 같은 관절의 최신 외관을 포함하는 영역을 더 강조한다는 것을 관찰할 수 있습니다. 3개의 프레임에서 연속해서 움직입니다(col. 4). 이 두 부분은 새 메모리로 결합되고 새 메모리는 높은 신뢰도로 새 프레임에 대한 예측을 생성합니다(col. 5). 그렇기 때문에 모델은 시간적 지오메트릭 일관성을 포착하고 그림 1에서 설명한 것처럼 비디오의 실수를 방지할 수 있습니다.
두 번째 샘플의 경우 첫 번째 프레임에서 왼쪽 손목을 볼 수 있지만 다음 두 프레임에 가려집니다. 저희 모델에서, 왼쪽 손목이 첫 번째 프레임에서 인식되었기 때문에, 다음 프레임은 마지막 단계의 메모리 셀로 그것의 위치를 유추할 수 있습니다. 더욱이, 세 번째 샘플에서 팔꿈치의 움직임은 휙휙 소리를 내지만, 모델은 정적 관절(예: 고관절과 예리함)을 유지할 수 있고, 기억 세포와 새로운 입력에 의해 빠르게 움직이는 관절(예: 팔꿈치)의 새로운 정보를 빠르게 추적할 수 있습니다.
결론적으로, 이러한 메커니즘은 비디오에서 포즈 추정을 위해 예측을 보다 정확하고 강력하게 만드는 데 도움이 될 수 있습니다.
5. 결론
본 논문에서, 비디오 포즈 추정을 위해 LSTM과 함께 새로운 반복 CNN 모델을 제시했습니다. 정확성과 효율성 측면에서 모두 상당한 향상을 이뤘습니다. 관절이 오랫동안 보이지 않을 때 몇 가지 잘못된 예측을 관찰했지만, LSTM 모듈이 시간적 정보의 더 나은 활용에 실제로 기여했고 비디오 전체에서 안정적이고 정확한 예측을 했다는 것을 발견했습니다. 결국 LSTM 내부의 메모리 셀을 탐색하고 시각화했으며 프레임 변경에 대한 포즈 추정 중 메모리의 기본 역학에 대해 설명했습니다.




댓글