Abstract
비디오에서 다인칭 포즈 추정을 위한 현대적인 접근 방식은 많은 양의 고밀도 주석을 필요로 합니다. 그러나 비디오의 모든 프레임에 라벨을 부착하는 것은 비용이 많이 들고 노동력이 많이 듭니다. 고밀도 주석의 필요성을 줄이기 위해, 고밀도 시간적 포즈 전파 및 추정을 수행하는 방법을 배우기 위해 sparsely labeled train 비디오(매 k 프레임)를 활용하는 PoseWarper 네트워크를 제안합니다. 비디오 프레임 쌍(프레임 A와 라벨이 부착되지 않은 프레임 B)이 주어진 경우, A와 B 사이의 포즈 뒤틀림을 암묵적으로 학습하기 위해 프레임 B의 기능을 사용하여 프레임 A에서 인간의 자세를 예측하도록 모델을 훈련합니다. 훈련된 PoseWarper를 여러 애플리케이션에 활용할 수 있음을 보여 줍니다. 첫째, 추론 시 수동으로 주석을 단 프레임에서 레이블이 지정되지 않은 프레임으로 포즈 정보를 전파하기 위해 네트워크의 애플리케이션 방향을 반전할 수 있습니다. 이렇게 하면 수동 레이블이 지정된 프레임 몇 개만 주어진 전체 비디오에 대한 포즈 주석을 생성할 수 있습니다. optical flow에 기반한 현대의 라벨 전파 방식과 비교해 볼 때, warp 메커니즘은 훨씬 더 컴팩트하고(매개 변수 6M 대 39M) 더 정확합니다(88.7% mAP 대 83.8% mAP). 또한 기존의 수동 라벨에 전파된 포즈를 추가하여 얻은 증강 데이터셋을 교육함으로써 포즈 추정기의 정확도를 향상시킬 수 있음을 보여줍니다. 마지막으로, PoseWarper를 사용하여 추론하는 동안 인접 프레임에서 임시 포즈 정보를 수집할 수 있습니다. 이를 통해 PoseTrack2017 및 PoseTrack2018 데이터셋에 대한 최신 포즈 감지 결과를 얻을 수 있습니다. 코드는 https://github.com/facebookresearch/PoseWarper에서 사용할 수 있습니다.
- Introduction
최근 몇 년 동안 시각적 이해 방법 [1–15]이 엄청난 발전을 이루었습니다. 일부는 딥러닝[16–19]의 발전과 대규모 주석 데이터셋의 도입에 기인했습니다[20, 21]. 본 논문에서는 최근 대규모 데이터셋의 생성으로 큰 이익을 얻고 있는 포즈 추정의 문제를 고려합니다 [22, 23]. 그러나, 이 분야에서 최근 발전한 대부분의 논문은 정지 이미지에서의 포즈 평가 작업에 집중되어 왔습니다 [3, 23–27]. 그러나 motion blur, video defocus, frequent pose occlusions 와 같은 요소로 인해 이러한 이미지 레벨 모델을 비디오에 직접 적용하는 것은 어렵습니다. 또한 주석이 달린 포즈 데이터를 다인용 비디오로 수집하는 프로세스에는 비용과 시간이 많이 소요됩니다. 비디오에는 일반적으로 인간 주석기가 레이블을 조밀하게 지정해야 하는 수백 개의 프레임이 포함되어 있습니다. 그 결과, 비디오 포즈 추정을 위한 데이터 세트[22]는 일반적으로 이미지 데이터 세트[21]에 비해 작고 다양하지 않습니다. 이는 현대의 심층 모델에서는 우수한 성능을 얻기 위해 대량의 레이블 데이터가 필요하기 때문에 문제가 됩니다. 동시에, 비디오는 프레임마다 콘텐츠가 거의 변하지 않기 때문에 정보 중복성이 높습니다. 이로 인해 좋은 포즈 추정 정확도를 얻기 위해 교육 비디오의 모든 프레임에 라벨을 부착해야 하는지에 대한 의문이 제기됩니다.
densely annotated 비디오 포즈 데이터에 대한 의존도를 줄이기 위해 본 연구에서는 sparsely annotated 비디오, 즉 포즈 주석이 k 프레임마다만 제공되는 비디오에서 작동하는 Pose-Warper 네트워크를 소개합니다. 동일한 비디오의 프레임 쌍(레이블 A와 레이블 B가 없는 프레임)이 주어진 경우, 프레임 B의 기능을 사용하여 프레임 A의 포즈를 감지하도록 모델을 교육합니다. 이러한 목표를 달성하기 위해 공간과 시간에 걸쳐 변형 가능한 컨버전스[28]를 활용합니다. 이 메커니즘을 통해 이 모델은 라벨이 부착되지 않은 프레임 B에서 피쳐 샘플링을 학습하여 라벨이 부착되지 않은 프레임 A에서 포즈 감지 정확도를 극대화합니다. 그런 다음 훈련된 PoseWarper를 여러 응용 프로그램에 사용할 수 있습니다. 첫째, PoseWarper를 활용하여 몇 개의 수동으로 레이블이 지정된 프레임의 포즈 정보를 전체 비디오에 전파할 수 있습니다. FlowNet2[29]와 같은 최신 optical flow 방법과 비교했을 때, PoseWarper는 보다 정확한 자세 주석(88.7% mAP 대 83.8% mAP)을 생성하는 동시에 훨씬 더 컴팩트한 왜곡 메커니즘(6M 대 39M 매개변수)을 사용합니다. 또한, 전파된 포즈가 보다 정확한 포즈 감지기를 훈련시키는 효과적인 의사 라벨의 역할을 할 수 있다는 것을 보여줍니다. 마지막으로, PoseWarper를 사용하여 추론하는 동안 인접 프레임에서 임시 포즈 정보를 집계할 수 있습니다. 따라서 개별 프레임의 폐색 또는 모션 흐림에 대한 접근 방식이 보다 강력해지고 PoseTrack 2017 및 PoseTrack 2018 데이터셋에 대한 첨단 포즈 감지 결과가 도출됩니다 [22].
- Related work
Multi-Person Pose Detection in Images. 포즈 추정을 위한 전통적인 접근법은 그림 구조 모델[30–34]을 활용합니다. 그림 구조 모델은 연결된 신체 부위 사이에 쌍을 이룰 가능성이 있는 tree-structured graph로서 인체를 나타냅니다. 이러한 접근법은 과거에는 매우 성공적이었지만 신체 일부가 가려지면 실패하는 경향이 있습니다. 이러한 문제들은 tree가 아닌 그래프 구조를 가정하는 모델에 의해 부분적으로 해결되었습니다 [35–38]. 그러나, 단일 영상 포즈 추정을 위한 대부분의 현대적인 접근법은 컨볼루션 신경망에 기초합니다 [3, 6, 23– 27, 39–45]. [3]의 메서드는 영상에서 직접 (x, y) 관절 좌표를 회귀 분석합니다. 보다 최근의 작업[25]에서는 포즈 heatmap를 예측하여 최적화 문제를 더 쉽게 해결할 수 있습니다. 여러 가지 접근 방식[24, 26, 39, 46]은 예측이 CNN 내부 또는 반복 네트워크를 통해 서로 다른 단계에서 조정되는 반복적인 포즈 추정 파이프라인을 제안합니다. [6, 23, 45]의 방법들은 하향식 방식으로 포즈 추정 문제를 해결하며, 먼저 사람의 bounding box를 감지한 다음 잘라낸 이미지에서 포즈 heatmap을 예측합니다. [24]의 작업은 서로 다른 신체 부위 간의 pairwise 관계를 캡처하는 부품 선호도 필드(part affinity fields) 모듈을 제안합니다. [42, 43]의 접근 방식은 먼저 핵심 포인트를 예측한 다음 이를 인스턴스로 통합하는 상향식 파이프라인을 활용합니다. 마지막으로, [27]의 최근 연구는 고해상도 피쳐 맵을 보존하는 아키텍처를 제안하고 있으며, 이는 다인용 포즈 추정 작업에 매우 유익한 것으로 나타났습니다.
Multi-Person Pose Detection in Video. 비디오 포즈 감지를 위한 대규모 벤치마크의 수가 제한되었기 때문에 비디오 도메인에는 훨씬 적은 방법이 사용되었습니다. 여러 이전 방법[22, 47, 48]은 개별 프레임의 핵심 포인트를 먼저 감지한 다음 시간적 smoothing 기법을 적용하는 2단계 문제로 비디오 포즈 추정 작업을 처리합니다. [49]의 방법은 비디오의 포즈 예측에 공동으로 최적화된 시공간 CRF를 제안합니다. [50]의 작업은 각 비디오에서 신뢰도가 높은 핵심 포인트를 가진 몇 개의 프레임에서 모델을 세밀하게 조정함으로써 달성되는 개인화된 비디오 포즈 추정 프레임워크를 제안합니다. [51, 52]의 접근 방식은 여러 프레임에 걸쳐 일시적으로 기능을 정렬한 다음 개별 프레임에서 포즈 감지를 위해 aligned features을 사용하기 위한 흐름 기반 표현을 활용합니다.
이러한 이전 방법과는 달리, 주된 목표는 sparsely labeled 비디오에서 효과적인 비디오 포즈 감지기를 배우는 것입니다. aligned feature에 흐름 표현을 사용하는 [51, 52]의 방법과 유사합니다. 그러나, 이 모델과는 달리, [51, 52]의 방법들은 자세 감지 작업과 관련하여 전체적인 흐름 표현을 최적화하지 않습니다. 이는 강한 성과를 위해 중요합니다.
- The PoseWarper Network

- 그림 1. 자세 감지를 위해 sparsely labeled 비디오를 사용하는 방법에 대한 개략적인 개요입니다. 그림의 얼굴은 사생활 보호를 위해 인위적으로 마스크됩니다. 각 교육 비디오에서 포즈 주석은 모든 k 프레임에서만 사용할 수 있습니다. 교육 중에 저희 시스템은 프레임 A와 라벨이 부착되지 않은 프레임 B의 한 쌍을 고려하며, 프레임 B의 기능을 사용하여 프레임 A의 포즈를 감지하는 것을 목표로 합니다. train 절차는 두 가지 목표를 달성하기 위해 고안되었습니다. 1) 이 두 프레임과 관련된 모션 오프셋을 추출할 수 있어야 합니다. 2) 모션 오프셋을 사용하여 모델은 라벨이 부착되지 않은 Frame B에서 추출한 검출된 포즈 heatmap을 다시 reverse할 수 있어야 Frame A에서 포즈 감지 정확도를 최적화할 수 있습니다. train 후 모델을 역순으로 적용하여 몇 프레임에 대해서만 제공된 ground truth 포즈에서 전체 비디오에 포즈 정보를 전파할 수 있습니다.
Overview. sparsely labeled 비디오에서 포즈 감지법을 배우는 모델을 디자인하는 것이 목표입니다. 특히, 교육 비디오의 포즈 주석은 k프레임마다 사용할 수 있다고 가정합니다. 얼굴 속성 임베딩을 학습하기 위한 최근 자체 감독 방식[53]에서 영감을 받아 다음 작업을 공식화합니다. Frame A(프레임 A)와 Frame B(프레임 B)라는 두 개의 비디오 프레임이 주어졌을 때, Frame A와 Frame B(프레임 A의 포즈)를 비교하는 것이 허용되지만, 그림 1(상단)과 같이 Frame B의 특징을 사용하여 Pose A(즉 Frame A의 포즈)를 예측해야 합니다.
언뜻 보기에 이 작업은 지나치게 어려워 보일 수 있습니다. Frame B의 기능만 사용하여 Pose A를 어떻게 예측할 수 있을까요? 하지만, 프레임 A와 프레임 B 사이에 신체 관절 correspondences가 있었다고 가정해보면, 단순히 프레임 B와 프레임 A 사이의 correspondences 집합에 따라 프레임 B에서 계산된 피쳐 맵을 공간적으로 "뒤틀기warp"만 하면 되기 때문에, 이 작업은 사소한 것이 될 것입니다. 이러한 직관력을 바탕으로 1) Frame A와 Frame B를 비교하여 이 두 프레임과 관련된 모션 오프셋을 추출할 수 있는 학습 방식을 설계합니다. 2) 이러한 모션 오프셋을 사용하여 Frame A에서 자세 감지 정확도를 최적화하기 위해 라벨이 부착되지 않은 Frame B에서 추출한 자세를 모델이 다시 반전할 수 있어야 합니다.
이러한 목표를 달성하기 위해 먼저 각 프레임에 대한 포즈 heatmaps를 예측하는 백본 CNN을 통해 두 프레임을 모두 제공합니다. 그런 다음 두 프레임의 결과 heatmaps를 사용하여 프레임 A에서 검출하기 위해 프레임 B에서 샘플링해야 하는 점을 결정합니다. 마지막으로, Frame B의 다시 샘플링된 포즈 heatmaps를 사용하여 포즈 A의 정확도를 극대화합니다.
Backbone Network. 높은 효율성과 정확성으로 인해, High Resolution Network(HRNet-W48)[27]를 백본 CNN으로 사용합니다. 그러나 이 시스템은 다른 아키텍처도 쉽게 통합할 수 있습니다. 따라서, 향후 스틸 이미지 포즈 추정의 개선이 이 접근법의 효과를 더욱 향상시킬 것으로 예상합니다.
Deformable Warping. 처음에, 프레임 A와 프레임 B를 백본 CNN을 통해 공급합니다. CNN은 heatmap fA와 fB를 출력합니다. 그런 다음 $ψ_{A,B} = f_{A} − f_{B}$의 차이를 계산합니다. 결과 피쳐 텐서 $ψ_{A,B}$는 피쳐 텐서 $φ_{A,B}$를 출력하는 3 × 3개의 단순 residual 블록(표준 ResNet-18 또는 ResNet-34 모델) 스택에 입력으로 제공됩니다. 그런 다음 기능 텐서 $φ_{A,B}$를 각각 다른 확장 속도 $d ∈ {3, 6, 12, 18, 24}$를 사용하여 5개의 3 × 3 컨볼루션 레이어로 공급하여 모든 픽셀 위치 p_n에서 5개의 오프셋 $o^{(d)}(p_n)$을 예측합니다. 오프셋 예측 단계에서 서로 다른 확장 속도를 사용하는 동기는 서로 다른 공간 척도에서의 모션 신호를 고려해야 하기 때문입니다. 몸의 움직임이 작을 때, 미세한 움직임 신호를 포착하기 때문에 더 작은 확장 속도가 유용할 수 있습니다. 반대로, 몸의 움직임이 클 경우, 큰 확장 속도를 사용하면 관련 정보를 더 멀리 통합할 수 있습니다. 다음으로, 예측된 오프셋은 포즈 heatmap $f_B$를 공간적으로 다시 뒤틀기 위해 사용됩니다. 5개의 오프셋 $o^{(d)}$ 각각에 대해 이 작업을 수행한 다음 5개의 리워프된 포즈 heatmaps를 모두 합산하여 프레임 A의 포즈 예측에 사용되는 최종 output $g_{A,B}$를 얻습니다.
Loss Function. [27]과 같이 predicted 와 ground-truth heatmaps 사이의 평균 제곱 오차를 계산하는 표준 포즈 추정 손실 함수를 사용합니다. ground-truth heatmaps는 각 joint 위치 주위에 2D 가우스를 적용하여 생성됩니다.
Pose Annotation Propagation. train 중에 모델이 라벨이 부착되지 않은 프레임 B에서 heatmap $f_B$를 왜곡하여 라벨이 부착된 프레임 A의 heatmap과 일치하도록 합니다. 그 후에, 네트워크의 적용 방향을 바꿀 수 있습니다. 그런 다음 manual annotated 프레임에서 레이블이 지정되지 않은 프레임(즉, 레이블이 지정된 프레임 A에서 레이블이 지정되지 않은 프레임 B로)으로 포즈 정보를 전파할 수 있습니다. 구체적으로, 프레임 A에서 포즈 annotation이 주어졌을 때, 각 joint의 위치 주변에 2D 가우스([23, 27]에서 수행된 방식과 동일)를 적용하여 각각의 ground-truth heatmap $y_A$를 생성할 수 있습니다. 그런 다음 feature 차이 $ψ_{B, A} = f_B - f_A$에서 레이블이 지정되지 않은 프레임 B에 대한 ground-truth heatmap $y_A$의 warp를 예측할 수 있습니다. 마지막으로, 변형 가능한 뒤틀림 방식(deformable warping scheme)을 사용하여 ground-truth pose heatmap A를 프레임 B로 뒤틀어서 포즈 주석을 동일한 비디오의 레이블이 없는 프레임에 전파합니다. 이 방식에 대한 개략적인 설명은 그림 1 참조.

- 그림 3: PoseWarper 및 FlowNet2의 비디오 포즈 전파 작업 결과 [29]. 각 3-프레임 시퀀스의 첫 번째 프레임은 시간 t에서 라벨이 지정된 기준 프레임을 나타냅니다. 단순성을 위해 각 프레임에 분홍색 원으로 표시된 한 사람의 "오른쪽 발목" 신체 관절만 표시합니다(확대하여 더 잘 보이도록 하십시오). 두 번째 프레임은 시간 t에 라벨이 부착된 프레임에서 시간 t+1에 라벨이 부착되지 않은 프레임으로 전파된 "오른쪽 발목" 탐지를 나타냅니다. 세 번째 프레임은 FlowNet2 기준선에 의해 생성된 프레임 t+1의 전파된 탐지를 보여줍니다. 이방법과 달리, FlowNet2는 큰 모션, 흐림 또는 막힘이 있을 때 자세를 전파하지 못합니다.
Temporal Pose Aggregation at Inference Time. 모델을 사용하여 training 비디오에 포즈 annotation을 전파하는 대신, 포즈 감지의 정확성을 높이기 위해 추론하는 동안 deformable warping 메커니즘을 사용하여 근처 프레임의 포즈 정보를 집계할 수도 있습니다. 시간 t에 있는 모든 프레임에 대해 t + δ 간에 모든 프레임에서 정보를 수집하고 $(δ ∈ {−3, −2, −1, 0, 1, 2, 3})$ 이러한 포즈 집계 절차는 occlusions, motion blur, and video defocus에 대한 추정치를 더욱 견고하게 만듭니다.
한 쌍의 프레임, $I_t$과 $I_{t+δ}$를 생각해 보십시오. 이 경우, 프레임 $I_{t+ δ}$의 포즈 정보를 사용하여 프레임 $I_t$의 포즈 감지를 개선하고자 합니다. 이를 위해 먼저 훈련된 PoseWarper 모델을 통해 두 프레임을 모두 공급하고 프레임 $I_{t+δ}$ frame의 특징을 사용하여 $I_t$ 프레임에 대해 정렬된 공간적으로 리워프된(다시 샘플링된) 포즈 heatmap $g_{t,t+ δ}$를 얻습니다. 모든 δ 값에 대해 이 절차를 반복한 다음 합계 $\sum_δg_{t,t+ δ}$ 를 통해 여러 프레임에서 포즈 정보를 집계할 수 있습니다.
Implementation Details. [27]의 프레임워크에 따라, train을 위해 각 개인 주위에 384 × 288 경계 상자를 자르고 모델에 입력으로 사용합니다. 훈련 중에 gt bbox를 사용합니다. 또한 랜덤 회전, 스케일링 및 수평 플립을 사용하여 데이터를 확대합니다. 네트워크를 학습하기 위해 기본 학습률이 $10^{-4}$인 Adam Optimizer[54]를 사용합니다. 이 값은 각각 10, 15epoch 이후 $10^{-5}$와 $10^{-6}$로 감소됩니다. 교육은 4개의 Tesla M40 GPU를 사용하여 수행되며, 20개의 epoch 이후 종료됩니다. COCO 핵심 포인트 추정 작업에 대해 사전 교육을 받은 HRNet-W48[27]로 모델을 초기화합니다. Deformable warping 모듈을 train하기 위해, 프레임 A에 상대적인 임의의 시간 간격 $δ ∈ [−3, 3]$을 가진 프레임 B를 선택합니다. 두 프레임과 관련된 features을 계산하기 위해서는 각각 128개의 채널을 가진 20개의 3 × 3 residual blocks을 사용합니다. 많은 콘볼루션 레이어처럼 보이지만, 각 레이어에서 적은 수의 채널로 인해, 5.8M 파라미터를 갖습니다([29]에서 optical flow을 계산하는 데 필요한 39M과 비교). 오프셋 o^{(d)}를 계산하기 위해 각각 다른 확장률$(d = 3, 6, 12, 18, 24)$을 사용하는 5개의 3 × 3 컨볼루션 레이어를 사용합니다. 포즈 heatmap f_B를 다시 샘플링하기 위해, 5개의 3 × 3 변형 컨볼루션 레이어를 사용합니다. 각 레이어는 예측된 5개의 오프셋 맵 중 하나에 적용됩니다. 5개의 변형 가능한 컨볼루션 레이어도 3, 6, 12, 18, 24의 서로 다른 확장dilation 속도를 사용합니다. 테스트하는 동안 [27, 23]에서 사용한 것과 동일한 2단계 프레임워크를 따릅니다. 먼저 [48]의 디텍터를 사용하여 이미지 내 각 개인에 대한 bbox를 감지한 다음 잘라낸 이미지를 포즈 추정 모델에 공급합니다.
- Experiments
이 섹션에서는 PoseTrack [22] 데이터 세트에 대한 결과를 제공합니다. 1) video pose propagation, 2) 전파된 포즈 의사 레이블로 augmented된 annotation으로 네트워크 train, 3) 추론 중 시간 포즈 집계의 세 가지 애플리케이션에 대한 접근 방식의 효과를 입증합니다.
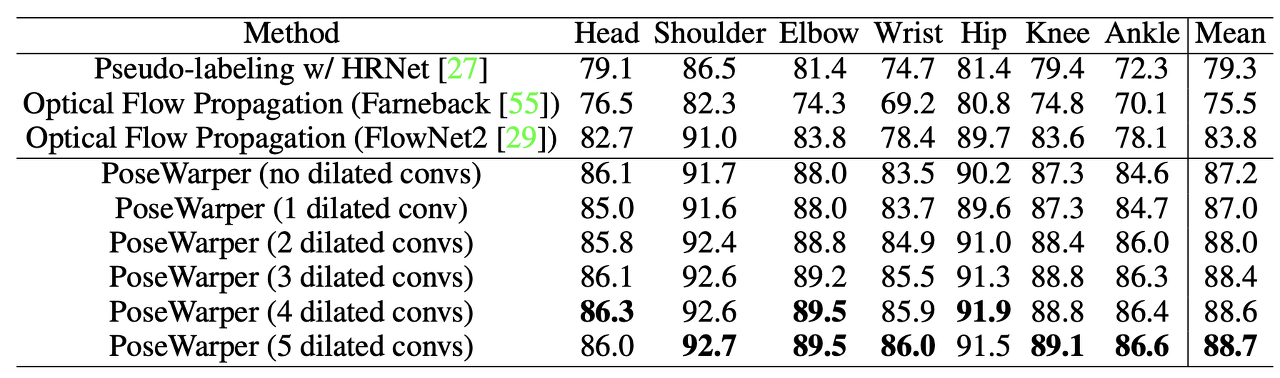
- 표 1. PoseTrack 2017 [22] 유효성 검사 세트(mAP로 측정)에서 비디오 포즈 전파의 결과입니다. 당사는 몇 프레임으로 제공되는 수동 주석에서 전체 비디오에 걸쳐 포즈 정보를 전파합니다. PoseWarper 아키텍처에서 서로 다른 수준의 확장 컨볼루션 효과를 연구하기 위해 몇 가지 절제 기준도 포함합니다(표 하단 참조).
4.1 Video Pose Propagation
Quantitative Results. 모델이 포즈 correspondences을 캡처하는 방법을 학습하는지 확인하기 위해, 비디오 포즈 전파, 즉 라벨이 부착된 몇 개의 프레임에서 여러 시간에 걸쳐 포즈를 전파하는 작업에 이를 적용합니다. 처음에는 위에 설명된 절차에 따라 sparsely labeled 비디오 설정에서 PoseWarper를 train합니다. 이 설정에서는 교육 비디오의 7번째 프레임마다 레이블이 지정됩니다. 즉, 수동으로 레이블이 지정된 각 프레임 쌍 사이에는 레이블이 지정되지 않은 프레임 6개가 있습니다. 각 비디오에는 평균 30개의 프레임이 포함되어 있기 때문에 각 비디오에는 약 5개의 주석 프레임이 균일한 간격으로 배치되어 있습니다. 따라서 학습된 PoseWarper를 사용하여 수동으로 레이블이 지정된 프레임에서 레이블이 지정되지 않은 모든 프레임으로 포즈 주석을 동일한 비디오에 전파하는 것이 목표입니다. 특히, 비디오의 각 라벨링된 프레임에 대해 이전 프레임 3개와 이후 프레임 3개로 포즈 정보를 전파합니다. PoseTrack2017[22]의 교육 세트에서 sparsely labeled 비디오에 대해 PoseWarper를 교육한 다음 검증 세트에서 평가를 수행합니다. 접근법의 효과를 평가하기 위해, 모델을 여러 관련 baseline과 비교합니다. 가장 약한 기준으로 훈련된 HRNet [27] 모델을 사용합니다. 이 모델은 단순히 비디오의 모든 프레임에 대한 자세를 예측합니다. 또한 optical flow을 사용한 왜곡 주석을 기반으로 한 몇 가지 전파 기준도 포함되어 있습니다. 그 중 첫 번째는 표준 Farneback optical flow[55]을 사용하여 라벨이 부착된 각 프레임의 포즈를 이전 프레임과 이후 프레임 세 개로 뒤틀립니다. 또한 FlowNet2 optical flow을 사용하는 보다 발전된 optical flow 기준도 포함합니다 [29]. 마지막으로 PoseWarper 모델을 평가합니다. 표 1에서는 비디오 포즈 전파에 대한 정량적 결과를 제시합니다. 평가는 [42]와 같이 mAP 메트릭을 사용하여 수행됩니다. 최고 모델은 88.7% mAP를 달성하는 반면, FlowNet2[29]를 사용하는 optical flow 기준선은 83.8% mAP의 정확도를 제공합니다. 또한, FlowNet2 [29] 전파 기준선에 비해 PoseWarper Warping 메커니즘은 더 정확할 뿐만 아니라 훨씬 더 컴팩트합니다(6M 대 39M 매개변수).
Ablation Studies on Dilated Convolution. 표 1에서는 PoseWarper 아키텍처에서 서로 다른 수준의 확장 컨볼루션 효과를 조사한 결과도 제시합니다. 비디오 포즈 전파 작업에서 이 모든 변형을 평가합니다. 첫째, 원래 아키텍처에서 dilated 컨볼루션 블록을 제거하면 정확도가 88.7mAP에서 87.2mAP로 감소한다고 보고합니다. 또한 단일 확장 컨볼루션(확장 속도 3 사용)을 사용하는 네트워크는 87.0mAP를 산출합니다. 두 번째 확장 컨볼루션 수준(확장율 3, 6 사용)을 추가하면 정확도가 88.0으로 향상됩니다. 세 가지 확장 수준(확장 속도 3, 6, 12)은 mAP 88.4이고 네 가지 수준(확장 속도 3, 6, 12, 18)은 mAP 88.6입니다. 5개의 확장 컨볼루션 레벨이 있는 네트워크는 88.7mAP를 산출합니다. 더 많은 확장 컨볼루션을 추가한다고 해서 성능이 더 향상되는 것은 아닙니다. 또한 1, 2, 3, 4, 5, 8, 16, 24, 32의 dilated rate를 사용하는 두 개의 네트워크를 실험하여 이러한 모델이 각각 88.6과 88.5의 mAP를 산출한다고 보고했습니다.
Qualitative Comparison to FlowNet2. 그림 3에서는 PoseWarper에 의해 인코딩된 모션의 그림을 포함하며 비디오 포즈 전파 작업을 위해 FlowNet2에서 계산한 optical flow와 비교합니다. 각 3-프레임 시퀀스의 첫 번째 프레임은 시간 t에서 라벨이 지정된 기준 프레임을 나타냅니다. 보다 깔끔한 시각화를 위해 프레임마다 분홍색 동그라미가 표시된 '오른쪽 발목' 신체 관절만 1인용으로 보여 줍니다. 두 번째 프레임은 시간 t에 라벨이 부착된 프레임에서 시간 t+1에 라벨이 부착되지 않은 프레임으로 전파된 "오른쪽 발목" 탐지를 나타냅니다. 세 번째 프레임은 FlowNet2 기준선에 의해 생성된 프레임 t+1의 전파된 탐지를 보여줍니다. 이러한 결과는 1) 큰 모션, 2) 막힘 또는 3) 흐릿한 경우 FlowNet2가 자세를 정확하게 왜곡하는 데 어려움을 겪는다는 것을 나타냅니다. 이와 대조적으로, 당사의 PoseWarper는 이러한 사례를 강력하게 처리하며, 이는 표 1의 결과(즉, 83.8 mAP w.r.t 대비 88.7)로도 알 수 있습니다. FlowNet2).
4.2 Data Augmentation with PoseWarper
여기서는 PoseWarper를 사용하여 희박하게 라벨이 지정된 train 비디오에 포즈를 propagate 한 다음, 이를 (원래 수동 라벨에 더하여) pseudo-ground truth labels로 사용하여 표준 HRNet-W48 [27]을 훈련하는 작업을 고려합니다. 이 실험을 위해 1) sparsely labeled 비디오의 총 수 및 2) 비디오당 수동으로 주석을 단 프레임 수, 두 변수의 함수로 포즈 감지 정확도를 연구합니다. 포즈 전달 메커니즘을 통해 수동 라벨링을 얼마나 줄이고 포즈 정확성을 유지할 수 있는지 연구하고자 합니다. 참고로, PoseTrack 2017의 교육 세트[22]에서 드물게 라벨이 붙은 비디오에 대해 PoseWarper를 먼저 train합니다. 그런 다음 동일한 교육 비디오 세트에 포즈 주석을 전파합니다. 그 후, sparsely manual 포즈 annotation 과 전파된 포즈로 구성된 공동 교육 세트에서 모델을 재교육합니다. 마지막으로 검증 세트에서 이 교육된 모델을 평가합니다.
모든 결과는 다양한 형태의 교육 데이터에 대해 교육된 표준 HRNet[27] 모델을 기반으로 합니다. "GT(1x)"는 gt annot만 사용하여 희박하게 라벨이 지정된 비디오에 대해 훈련된 모델을 말합니다. "GT(7x)" 기준선은 "GT(1x)"에 비해 7배 더 많은 수동 주석 자세를 사용합니다(주석은 PoseTrack 2017 교육 세트의 일부임). 이에 비해 접근 방식("GT (1x) + pGT (6x))은 희박한 수동 포즈 주석("GT (1x)" 기준과 동일)과 유사 gt 데이터(pGT)로 사용하는 전파된 포즈로 구성된 공동 훈련 세트에 대해 교육됩니다. 이전과 마찬가지로, 모든 라벨 프레임에 대해 gt 포즈를 이전 프레임 3개와 이후 프레임 3개로 전파하여 교육 세트를 7배 확장할 수 있습니다.

- 그림 4. 전파된 포즈 pseudo 라벨(왼쪽)을 사용하여 표준 HRNet을 교육하는 그림[27] 및 추론 중 시간 포즈 집계 체계입니다. 두 설정 모두에서 1) 희박하게 레이블이 지정된 교육 비디오 수(비디오당 수동으로 레이블이 지정된 프레임 수)와 2) 비디오당 레이블이 지정된 프레임 수(총 50개의 희박하게 레이블이 지정된 비디오 수)의 함수로 포즈 감지 성능을 연구합니다. 모든 기준선은 서로 다른 교육 세트에서 표준 HRNet [27] 모델을 재교육하는 것을 기반으로 합니다. "GT(1x)" 기준선은 희박하게 라벨이 지정된 비디오 데이터에 대해 표준 방식으로 교육됩니다. "GT(7x)" baseline은 "GT(1x)" baseline에 비해 manual annotation이 7배 더 많은 데이터를 사용합니다. 왼쪽 하위 그림("GT(1x) + pGT(6x))의 접근 방식에서는 전파된 포즈 유사 레이블(수동으로 레이블이 지정된 프레임마다 6개 근처 프레임)로 원본 sparsely labeled 비디오 데이터를 augment 합니다. 마지막으로, b) "GT (1x) + T-Agg"는 추론 중에 여러 인접 프레임의 포즈 정보를 결합하기 위해 PoseWarper를 사용하는 것을 나타냅니다("GT (1x)" 기준선에서와 같이 훈련이 수행됩니다. 결과를 통해 PoseWarper의 두 애플리케이션 모두 수동 주석 수를 줄이면서 강력한 포즈 정확도를 달성할 수 있는 효과적인 방법을 제공한다는 것을 알 수 있습니다.
그림 4의 왼쪽 하위 그림의 결과를 바탕으로 몇 가지 결론을 도출할 수 있습니다. 첫째, 라벨이 지정된 비디오가 매우 적으면(즉, 5개), 세 기준 모두 성능이 저하됩니다(맨 왼쪽 그림). 이는 이 설정에서 효과적인 포즈 감지 모델을 학습하기 위한 데이터가 충분하지 않음을 나타냅니다. 둘째, 레이블이 지정된 비디오의 수(예: 50 - 100)가 어느 정도 합리적일 경우, 이 접근 방식은 "GT(1x)" 기준선을 크게 능가하며 "GT(7x)" 기준선에 비해 약간 더 나쁠 뿐입니다. 라벨이 붙은 영상의 수가 늘어나면 세 가지 방법의 차이가 줄어들어 모델이 포화상태에 이른다는 것을 알 수 있습니다.

- 표 2: PoseTrack2017 및 PoseTrack2018 데이터 세트의 검증 및 테스트 세트에 대한 다중 사용자 포즈 추정 결과입니다. Sparsely labeled 비디오와 관련된 시나리오에서 포즈 감지를 개선하도록 설계되었지만, 여기서는 추론 중 시간적 포즈 집계 방식이 densely labeled 비디오에서 훈련된 모델에도 유용하다는 것을 보여줍니다. 최신 단일 프레임 baseline을 개선합니다 [23, 27, 56].
비디오당 레이블이 지정된 프레임의 수(가장 왼쪽 두 번째 그림)를 변화시키면 몇 가지 흥미로운 패턴을 볼 수 있습니다. 첫째, 비디오당 레이블이 지정된 프레임 수가 적은 경우(즉, 1 - 2) "GT(1x)" 기준보다 큰 폭으로 우수합니다. 둘째, 비디오당 2개 이상의 레이블이 지정된 프레임을 추가함에 따라 접근 방식과 "GT(7x)"의 성능이 매우 유사해집니다. 이러한 발견은 PoseWarper가 성능의 큰 손실 없이 주석 비용을 절감할 수 있다는 이전의 관찰 결과를 더욱 강화합니다.
4.3 Improved Pose Estimation via Temporal Pose Aggregation이 항목에서는 Pose Warper의 변형 변형 메커니즘을 사용하여 근처 프레임의 포즈 정보를 집계함으로써 테스트 시 포즈 추정의 정확도를 개선할 수 있는 능력을 평가합니다. 결과는 그림 4 b). 여기서 훈련된 a) 모델에 대한 추론 중 임시 자세 집계의 효과를 다른 수의 라벨링된 비디오(가장 오른쪽 그림)와 다른 수의 비디오(가장 오른쪽 그림)로 평가합니다. ("GT (1x) + T-Agg")을 이전 하위 섹션에 정의된 것과 동일한 "GT (7x)" 및 "1x" 기준선과 비교합니다. 이 경우 방법은 "GT (1x)" 기준선으로 정확하게 교육되어 있으며, 유일한 차이점은 추론 절차에서 나옵니다.
교육 비디오 및/또는 수동으로 레이블이 지정된 프레임 수가 적을 경우 NAT의 접근 방식은 "GT(1x)" 기준선에 대해 상당한 정확성을 향상시킵니다. 그러나 일단 레이블이 지정된 비디오/프레임의 수를 늘리면 세 기준선 사이의 격차가 줄어들고 모델은 더욱 포화 상태가 됩니다. 따라서, 추론 중 시간적 포즈 집계 체계는 희박하게 라벨이 붙은 비디오 설정에서 강력한 성능을 유지할 수 있는 또 다른 효과적인 방법입니다.
4.4 Comparison to State-of-the-Art
- 그림 5. 처음 두 열에는 모델의 입력으로 사용되는 비디오 프레임 쌍이 나와 있습니다. 세 번째 및 네 번째 열에는 모션 필드로 시각화된 임의로 선택된 두 오프셋 채널이 표시됩니다. 다른 채널은 다른 신체 부위의 움직임을 포착하는 것처럼 보입니다. 다섯 번째 열에는 눈에 띄는 인간의 움직임을 강조하는 오프셋 크기를 표시합니다. 마지막으로 마지막 두 열은 표준 Farneback 흐름과 학습된 오프셋에서 예측된 인간의 움직임을 보여줍니다. 사람의 움직임을 예측하기 위해 오프셋 맵에서 각 조인트의 ground-truth(x, y) 변위를 회귀시키는 선형 분류기를 훈련합니다. 오른쪽 하단에 있는 컬러 휠은 모션 방향을 인코딩합니다.
학습된 오프셋에 어떤 정보가 인코딩되어 있는지 이해하는 것은 다른 CNN 기능을 분석하는 것만큼 어렵습니다 [59, 60]. 주요 과제는 높은 차원의 오프셋에서 비롯됩니다. 5개의 확장 속도 d에 대해 각 픽셀에 대해 $c × k_h × k_w (x, y)$ 변위를 예측하고 있습니다. 여기서 c는 채널 수이고 $k_h , k_w$는 각각 컨볼루션 커널 높이 및 폭입니다.
그림 5의 3열, 4열에서는 무작위로 선택한 두 개의 오프셋 채널을 모션 필드로 시각화합니다. 이 그림에 따르면, 서로 다른 오프셋 맵이 모두 동일한 솔루션(예: 두 프레임 사이의 optical flow)을 예측하는 것이 아니라 서로 다른 모션을 인코딩하는 것으로 나타납니다. 이는 네트워크가 정보 없는 영역의 움직임을 무시하고 대신 서로 다른 오프셋 맵(예: 머리가 아닌 손)에 서로 다른 인체 부분의 움직임을 캡처하기로 결정할 수 있기 때문에 의미가 있습니다. 또한 학습된 오프셋의 크기는 중요한 인체 운동을 암호화합니다(그림 5의 5열 참조).
마지막으로 학습된 오프셋이 인체 모션을 인코딩하는지 확인하기 위해 신체 조인트를 나타내는 각 포인트 pn에 대해 예측 오프셋을 추출하고 선형 분류기를 훈련하여 이 신체 조인트의 gt (x, y) 운동 변위를 회귀 분석합니다. 그림 5의 7열에서는 모든 픽셀에 대한 예상 모션 출력을 시각화합니다. 6열에 판백의 optical flow을 보여줍니다 사람이 있는 지역의 경우 예상 인간의 움직임이 Farneback optical flow과 일치합니다. 뿐만 아니라 표준 Farneback optical flow에 비해 모션 필드의 noise이 적다는 점을 지적합니다.
- Conclusions
Sparsely labeled videos에서 포즈 감지를 위한 참신한 아키텍처인 PoseWarper. PoseWarper는 비디오 포즈 전파 및 임시 포즈 집계를 포함한 여러 애플리케이션에 효과적으로 사용할 수 있습니다. 이 접근방식이 강력한 포즈 감지 성능을 생성하는 동시에 densely labeled videos 데이터의 필요성을 감소시킨다는 것을 입증했습니다. 또한 PoseTrack2017 및 PoseTrack2018 데이터셋에 대한 최신 결과를 보면 교육 비디오에 라벨이 밀집되어 있는 경우에도 PoseWarper가 유용하다는 것을 알 수 있습니다. 향후 작업은 입력 프레임이 서로 떨어져 있을 때 라벨을 전파하고 시간 정보를 집계하는 모델 기능을 개선하는 것입니다. 또한 과제에 대한 자체 감독 학습 목표를 탐색하여 비디오에서 포즈 주석의 필요성을 더욱 줄일 수 있도록 하는 데에도 관심이 있다고 합니다.




댓글